
Pythonでの文字列の定義と表示に引き続いて、ここでは文字列の操作について扱っていきます。
文字列の操作には、分割、置換、検索など様々なものがあって、ここで全てを扱うことは当然ながら無理です。
ですから、基本的なものやよく見かけるもの中心に扱いたいと思います。ここで扱わなかったものは、今後のこのブログの中で行われる処理でその都度触れていこうと思います。
文字列のインデックス
文字列のインデックスから見ていきましょう。これはすでに文字列の表示のところで少しだけやりましたね。復習も兼ねてみておきましょう。

文字列は先頭の文字を「0」として順番に番号が位置として割り当てられています。この文字列の位置をインデックスと呼びます。
具体的には、「python」という文字列にインデックスを振ると次のようになります。
| p | y | t | h | o | n |
| 0 | 1 | 2 | 3 | 4 | 5 |
| -6 | -5 | -4 | -3 | -2 | -1 |
先頭の文字を「0」として「5」までインデックスが振られています。末尾の文字列を「-1」として逆方向に「-6」とも振ることができます。
先頭は「1」ではなく「0」から始まるというところに気をつけましょう。
このインデックスを利用して文字列を操作することもよくあります。
文字を抽出する
それではこのインデックスを使って、文字列の中から文字を抽出してみましょう。これには文字列を代入して変数の後ろに[]を使い、その中にオフセットを指定するという形をとります。
具体的にやってみましょう。まず文字列「python」を変数「word」に代入します。
word = "python"この「word」という変数の後ろに[]をつけて抽出したい文字列のインデックスを指定します。
word[0]
word[1]
word[-1]
word[-2]
word[10]それぞれ文字列の先頭、2番目、最後、最後から2番目、11番目を指定していることになります。
これを対話型シェルで実行すると、次のようになります。

それぞれのオフセットに対応した文字列が表示されているのがわかりますね。
word[10]に関してはエラーが出ています。
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
word[10]
IndexError: string index out of range「IndexError: string index out of range」ということで、文字列の長さを超えたインデックスを指定しているので抽出できないということですね。
文字列をスライスする
今度は文字列を部分的にスライスして抽出する方法をみていきます。先ほどの文字の抽出は[]の中に場所を指定しましたが、今度は「:」を使って分割する範囲を指定します。
形としてはこのようになります。
[start:end:step]
「start」の位置に抽出する文字の先頭のオフセットを指定します。「end」の位置に指定する数字で「end-1」番目の文字位置が指定されます。「step」は、その文字数毎に抜き出すという意味になります。
具体的にやってみた方がわかりますね。次のように任意の範囲を指定したコードを考えてみます。
word = "python"
word[0:3]
word[:3]
word[2:5]
word[2:]
word[-2:]
word[-4:-2]
words = "abcdefghijklmnopqrstuvwxyz"
words[::6]
words[2:21:4]これを対話型シェルで実行するとこうなります。
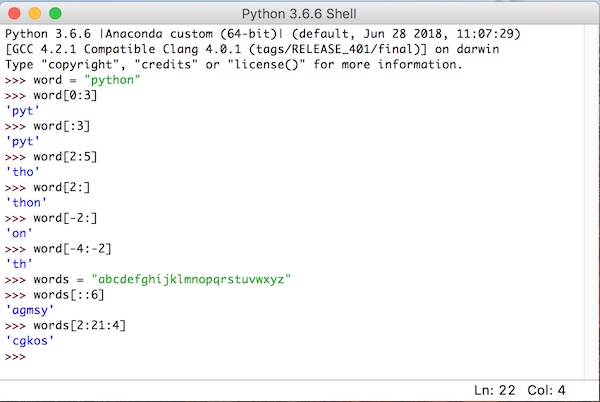
最初の2つは同じことを示します。先頭オフセットを指定しないと先頭から抽出します。この場合は先頭から3つ(インデックス−1番目)の文字を表示しています。
3つ目はオフセット2から5までの抽出で、3番目から5番目の文字を表示しています。
4つ目はオフセット2(3番目の文字)から末尾までの抽出です。
同様にマイナスのインデックスを使って2つ例を示してみました。
最後の2つはstepを利用しています。最後のstepだけを指定すると最初の文字から6文字毎に文字を抽出しています。最後は範囲指定した中で4文字毎に抽出した形になっています。
これらを操作するに当たっては、インデックスの数字と文字の位置がわかりにくいかもしれませんが、これには慣れておきましょう。
まとめ
文字列は先頭から順にインデックスが振られています。これを利用して文字列の操作をおこないました。
インデックスを利用すれば、その場所の文字を抽出することができます。また、スライスの機能とインデックスを利用して、任意の場所から任意の場所までの文字を抽出することもできます。
先頭の文字を1番目と考えることに慣れているので、インデックスの先頭が0であることにはしっかり慣れていくことにしましょう。

