Pythonプログラミングの基礎を学んできて、データの処理の方法はわかったと思います。ターミナルなどの画面に表示したり、出力する前ならメモリ内にデータが保持されています。
でも、パソコンの電源を落としてしまうとせっかく処理したデータは消えてしまって使えなくなります。データをいろんな目的に使うためには、あとで使えるようにしなければいけません。これを永続性などと言いますが、ファイルに保存することは誰でもすでにいろんなところでやっていますね。
ここではファイルの作成から入出力までの操作について学んでいきましょう。
ファイルの作成
データの保存の単純なものとしてはファイルです。ファイル名を指定して、そこにデータを格納し、データを読み出したり、ファイルに書き込んだりして作業するわけです。
では、ファイルを作成して行きましょう。
ファイルの保存場所は、自分の作業で都合の良いディレクトリにしましょう。ここではmy_fileというフォルダを用意して作業を進めていきます。このディレクトリでPythonを動かすことになります。
今は何のファイルも無い状態です。ファイルを扱うには、まずファイルを開くことから始めます。ファイルを開くことでファイルが作成されるわけです。次の形でファイルを作成します。
ファイルオブジェクト = open(“ファイル名”, “モード”)
open()を使ってファイル名をつけて、どんな操作のモードでファイルを開くかを指定して開き、それをオブジェクトで保持するという形です。
ファイルをopenするモードの部分には次のようなものが入ります。
- r:読み出し
- w:書き込み(上書きされます。ファイルが無い場合は新規ファイル作成。)
- x:ファイルが存在しない時だけ書き込み
- a:末尾に追記
モードの2文字目にはファイルのタイプ(t:テキスト、b:バイナリ)を入れたりします。
では実際にファイルを作成してみましょう。
ファイルを実際に作成してみよう!
作業はターミナルを使ってやってみましょう。作業ディレクトリに移動して、Pythonを起動します。(ここでは、Atomのターミナルを使って作業していきます。もちろんMac本体のターミナルから起動してもいいですし、対話型シェルを使っても構いません)

作成するファイル名をここでは、practice.txtというテキストファイルにしてみます。モードは”w”です。このとき、すでにこのファイルがあると書き換えられてしまうので注意しましょう。
次のコードをターミナルから入力してみましょう。
f = open("practice.txt", "w")
f.write("Python")
f.close()ファイルを作ってfというオブジェクトに入れています。それにwrite()を使って「Python」という文字列を書き込んでいます。最後にclose()を使ってファイルを閉じています。
この最後にclose()でファイルを閉じることを忘れないようにしましょう。
実際に入力してみるとこうなります。
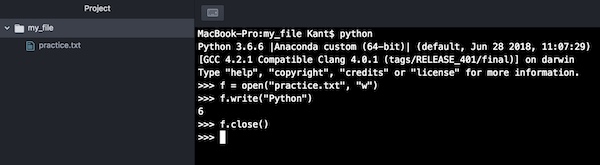
f.write()のところで、「6」と表示されていますが、これは書き込んだ文字数のことです。
左側のディレクトリ表示のところに、practice.txtが新しく作成されています。このファイルを開くと中に「Python」と書き込まれているのがわかります。
この作業、ターミナルのPythonシェルから行いましたが、コードをファイルに書いて実行しても同じ結果になります。
make_file.pyというファイル名でコードを保存してAtomで実行してみます。わかりやすいように作成中のテキストファイルを横に並べて表示させています。
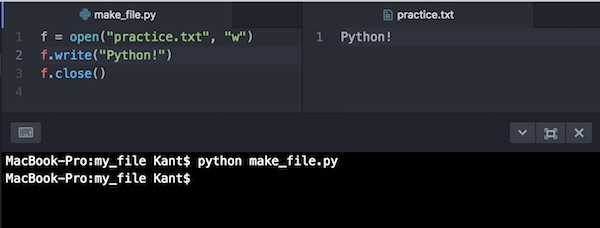
「Python」ではなく「Python!」とコードに書いて実行しまいたが、上書きされているのがわかります。同じ名前のファイルが存在すると、上書きされるので注意しましょう。
今度はモードを”a”にしてみます。(aはappendの意味ですね)
f = open("practice.txt", "a") # modeを"a"
f.write("Python!")
f.close()他のコードはそのままで実行するとこうなります。
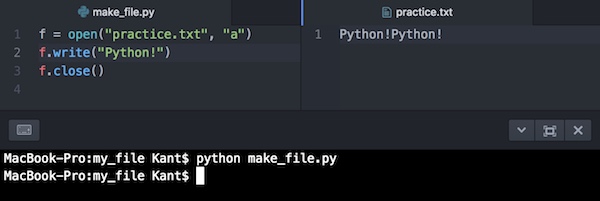
前の結果の後ろに「Python!」と追記されているのがわかります。
今度は次のように書き換えてみます。(モードを”w”に戻しています)
s = "ファイルの作成をしています。"
f = open("practice.txt", "w")
f.write("Python!\n")
print(s, file=f)
f.close()file=fでオブジェクトを指定して、print()で書き込みをしています。書き込む内容は、変数sに代入してみました。わかりやすいように、「Python!」のところに「\n」を使って改行を入れています。
実行するとこうなります。
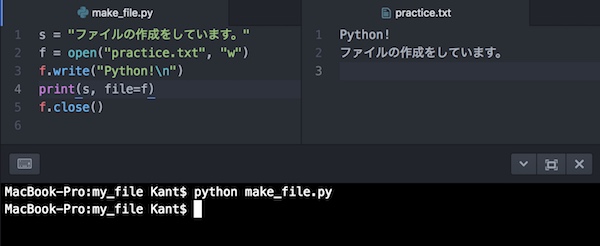
書き込みされているのがわかりますね。
print()はsepやendのオプションももちろん使えます。
print文に関してはこちらを復習しましょう。

ここでは、書き込みにはprint()ではなくwrite()を中心に使っていくことにします。
withステートメントでファイルを自動クローズ
ここまではファイルの操作で、このコードのように最後にclose()を置いていました。
f = open("practice.txt", "w")
f.write("Python!\n")
f.close()close()の記述を忘れるとメモリを使用したままになってしまうので、必ず書かないてファイルを閉じないといけないのですが、やはり忘れてしまうこともあります。
そこでwithステートメントという便利な仕組みがPythonにはあります。
with文を使って、上記のコードを書き換えてみましょう。
with open("practice.txt", "w") as f:
f.write("Python!\n")withを使ってopenで開き、asでオブジェク名を指定してコロンを置きます。インデントしてブロックコードにwrite()を書きます。close()は必要ありません。
実行するとこうなります。
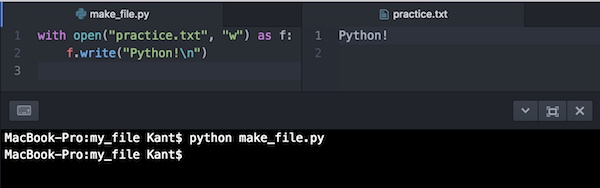
withはちょっと見慣れない感じですが、close()を使わなくてもファイルを自動的に閉じてくれるので、open()を使って開く時はwithを使っていくようにした方がいいでしょう。
ファイルの読み込み
次はファイルの読み込みをやってみましょう。
復習もかねて、withステートメントを使って次のようなコードでファイルを作ってみましょう。
sns = """Twitter #トリプルのクォーテーションで改行して複数行の値を作る
Facebook
YouTube
Instagram
Line
"""
with open("practice.txt", "w") as f:
f.write(sns)トリプルクォートで囲んで、複数のデータを改行を使って変数snsに入れています。これをwithを使ってファイルに書き込んでいます。
実行するとこうなります。
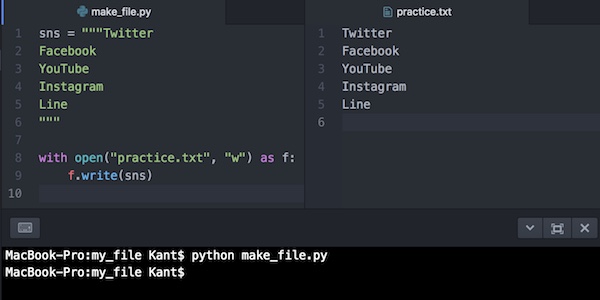
ファイルに書き込むことができました。
このファイルの中身を読み込むにはどうすればいいのが見て行きたいと思います。
read()でファイルを読み込む
作成したファイルのデータを読み込むにはread()を使って同じようにコードを書いて行きます。モードは”r”になります。(”r”はreadの意味)
上で作成さいたファイルを、次のコードで読み込んでみます。
with open("practice.txt", "r") as f:
print(f.read())ファイルを作成する時と同じように、withステートメントでファイルを開きます。読み込みなのでモードは”r”にします。ファイルオブジェクトのfとして扱って、read()で読み込んだものをprint()で出力しています。
これを実行すると、こうなります。
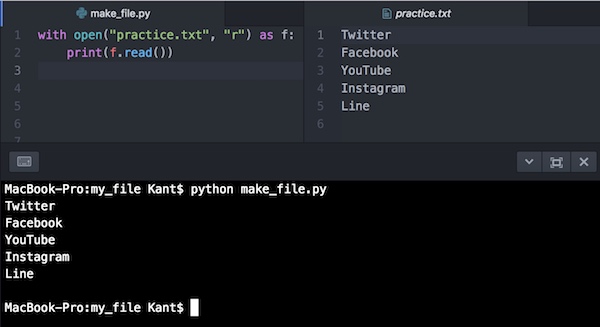
読み込まれたデータがターミナルに表示されているのがわかります。
こうしてファイルを読み込むことができました。
ただし、このread()のやり方はファイル全体を一気に読み込んでいるということに注意が必要です。なぜなら、これくらいのデータの容量ならまだ何も問題無いですが、ファイルの容量が数GBのようなものになると、それだけメモリの容量を消費してしまいます。
chunkの区切りで読み込む
何かの塊ごとに呼び出すようにすれば、メモリの消費がその都度になるので安全になります。そこでchunkを使います。(chunkは塊の意味です)
次のようにコードを書き換えます。
with open("practice.txt", "r") as f:
chunk = 3 # chukを3にして、3文字づつ取り出します。
while True: # whileループでchunkの塊毎に処理します。
fragment = f.read(chunk)
print(fragment)
if not fragment: # 塊がなくなったらループを抜けます。
breakchunkを3にして、ここでは3文字づつ取り出すことにします。whileループを使って、read()にchunkを指定して塊ごとにprintで出力することを繰り返します。塊が無くなったら、breakでwhileループを抜けます。
コードを実行するとこうなります。
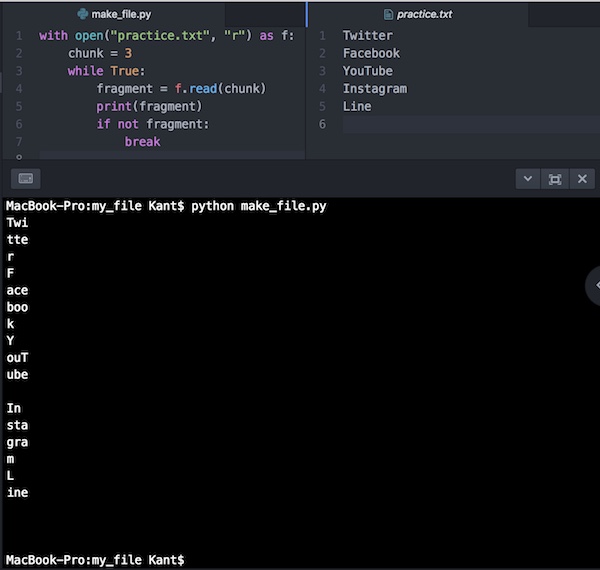
3文字づつ抜き出しているのがわかります。それぞれのライン毎に改行があり、print()での出力はデフォルトでは改行があるので、この改行もそれぞれ1文字と数えられているので、こういう出力になっています。
このchunkはデータのパケットのやり取りなどでも使うので覚えておきましょう。
readline()で1行づつ読み込む
次は1行づつ読み込む方法です。これにはreadline()を使います。
コードを次のように書き換えてみましょう。
with open("practice.txt", "r") as f:
while True:
line = f.readline() # readline()で1行づつ読み込み
print(line, end="") # デフォルトのend="\n"を削除しています。
if not line:
breakやり方はほとんど同じで、オブジェクトをleadline()で1行づつ取り出してwhileループを使ってprintで出力を繰り返しています。読み出す行のデータが無くなったらbreakでループを抜けています。ここではprint()にendオプションを使って行の最後にデフォルトで入っている改行を削除しています。
実行するとこうなります。
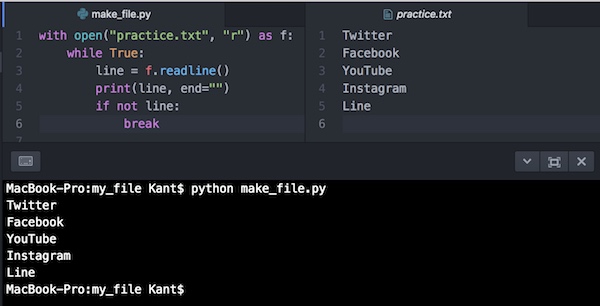
結果は一度に読み込んだ時と同じですが、内部的には1行づつ処理されています。これは1行づつ詠み込む毎に何か別の処理を行うと行ったプログラミングに使えます。
読み込む位置の変更
ファイルの読み込みはいつも先頭から読み込むわけではありません。任意の位置のデータから読み込んだりすることは当然あります。
ここでは、ファイル内の位置を管理して詠み込む方法を見ていきます。
tell()を使うと、現在の位置が先頭からどの位置になるのか、オフセットを返してくれる関数です。
同じファイルを次のようにtell()を使って開いてみましょう。
with open("practice.txt", "r") as f:
print(f.tell())実行するとこうなります。
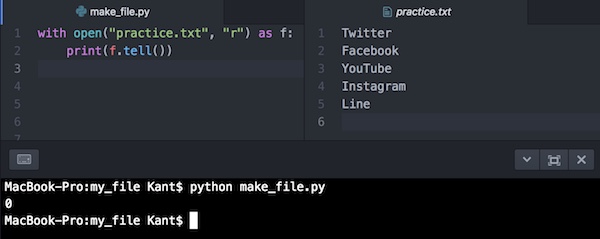
0と返されています。現在、データの一番先頭にいるということです。
この位置(ここでは先頭)から5文字読み込むには、read(5)とすればできることになっています。次のようにコードに加えてみましょう。
with open("practice.txt", "r") as f:
print(f.tell())
print(f.read(5))実行してみます。
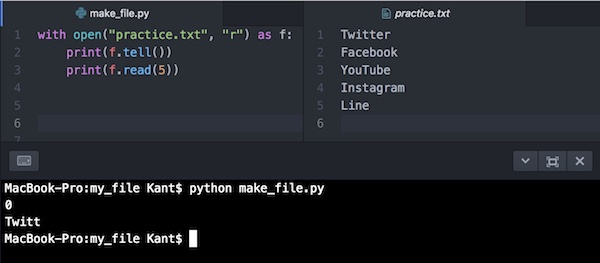
先頭から5文字を読み込んで出力しているのがわかります。
seek()で読み込む位置を移動する
では、これに続けて「Faceboo」と出力させる場合はどうすればいいでしょうか。
seek()を使うことでデータを読み込む位置を移動することができます。「Faceoo」のFの位置に移動したいわけですから、この位置を数えて見ると、0から始まって8番目になります。改行もカウントされていることに注意しましょう。そうなるとseek(8)で移動することになります。
「Faceboo」は7文字ですからread(7)です。
コードに追加してみましょう。
with open("practice.txt", "r") as f:
print(f.tell())
print(f.read(5))
f.seek(8)
print(f.read(7))実行するとこうなります。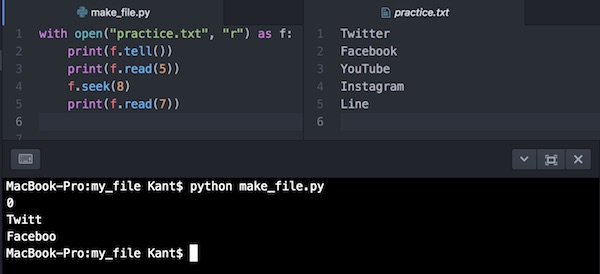
異動先からのデータが出力されているのがわかります。
ちなみにseek()は、オフセット値を与えるだけなら先頭からの位置ですが、第2引数に1を入れると現在の位置から、2を入れると末尾の位置から数えた位置に移動することができるようになっています。ただし、ここの場合のようにtextファイルの読み込みに対しては第2引数は使えません。seek(0, 2)の場合だけ、最後の位置に移動することはできます。(Python3の挙動)
まとめ
Pythonでせっかく作ったデータも何もしなければ、パソコンの電源を落とすとデータは失われてしまいます。そうならないようにデータを使えるように(永続化)しなければなりません。もっとも身近な方法はファイルとして保存することです。
ファイルはopen()を使ってファイル名を指定し、書き込みのモードを指定して作成したり、書き込みをしたりすることができます。データの書き込みはwrite()やprint()でできますが、write()を使うのが一般的でしょう。open()で開いた場合は、最後に必ずclose()でファイルを閉じる必要があります。
withステートメントでファイルを操作すれば、close()する必要はありません。自動でファイルを閉じてくれます。
ファイルの読み込みはread()で行います。小さいデータなら問題無いのですが、巨大なデータをそのまま読み込む場合、メモリの容量を大量に消費してしまうので、chunkやreadline()を使って塊や1行づつ読み込むことも必要です。
データはいつも先頭から読み込む訳ではありません。seek()を使うとデータを読み込む位置を変更することができます。

