
OpenCVを使ったPythonでの画像処理について、画像認識について扱っていきましょう。
これまでに、静止画から物体を認識をする方法としてテンプレートマッチングという手法をすでに扱いました。

これは、静止画像の一部分をテンプレート画像として利用し、それに一致する部分を静止画像から検出するのものでした。この手法は同じ画像を材料にしている為に、柔軟性のある方法ではありませんでした。
そこで、ここでは二枚目の画像中の特徴点の特徴量に基づいてマッチングする方法(特徴点マッチング、特徴量マッチング)を見て行こうと思います。
マッチングさせる2つの画像
まず、マッチングさせる2つの画像をjupyter notebookで読み込んで行きます。
ライブラリのインポートから始めましょう。
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineOpenCV、NumPy、Matplotlibをインポートしています。これはいつもの通りです。
画像の表示を関数としてまとめておきます。
def display(img,cmap='gray'):
fig = plt.figure(figsize=(12,10))
ax = fig.add_subplot(111)
ax.imshow(img,cmap='gray')display()関数を定義し、画像をわたし、グレースケールで表示するようにします。figure()で表示サイズを指定して、add_subplot()で画像を配置し、imshow()で表示します。
hacker = cv2.imread('images/book.jpg',0)imread()で画像を読み込みます。こちらは、まず1つ目の画像です。
display(hacker)先ほど定義した関数に渡して、画像を表示します。


ポール・グレアムの有名な本の表示の画像をここでは用意してみました。
もう一つ画像を用意します。
items = cv2.imread('images/books.jpg',0)
display(items)こちらもグレースケールで読み込んで表示します。
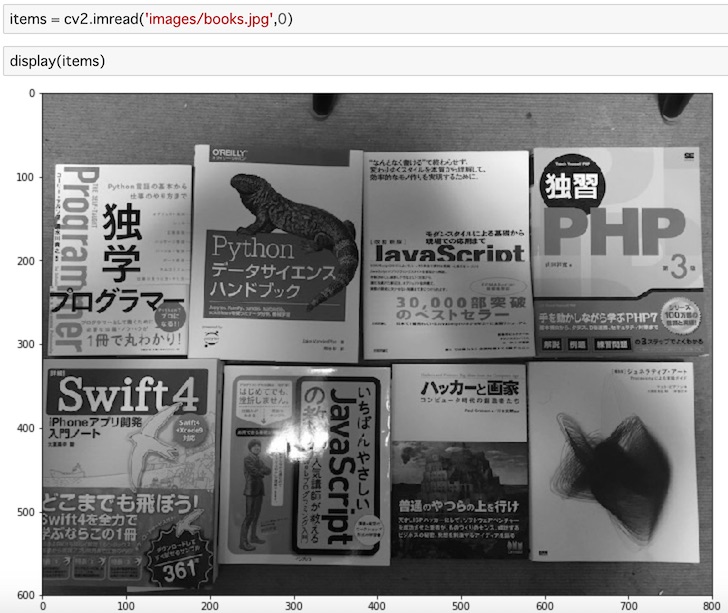
複数の本を適当に並べた画像を用意しました。この中に、先ほど表示したポール・グレアムの本も含まれていることを確認してください。
このナチュラルに並べた物体の中から、目的の画像を検出するのがここで行う特徴量マッチングです。テンプレートマッチングで使用した画像との違いですね。
ORBを使った総当りマッチング
まず、総当たりマッチング(Brute-Force matcher)を扱ってみます。
総当たりマッチングは、一つ目の画像の中のある特徴点の特徴量記述子を計算し、もう一つの画像の中にある全特徴点の特徴量から、ある距離計算に基づいてマッチングを行います。最も距離が小さい特徴点が対応する部分がマッチング結果として得られます。
次のようなコードになります。
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(hacker,None)
kp2, des2 = orb.detectAndCompute(items,None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
hacker_matches = cv2.drawMatches(hacker,kp1,items,kp2,matches[:25],None,flags=2)まず、cv2.ORB_create()でORB抽出器を初期化します。
これを使って画像のキーポイントと記述子を見つけていきます。detectAndCompute()の第1引数は特徴点を抽出する画像、第2引数は特徴点を抽出する領域を選択するマスクを指定しますが、ここではNoneを指定し画像全体から特徴点を抽出します。2つの画像の特徴的な点の位置(kp1, kp2)、特徴を現すベクトル(des1, des2)をそれぞれ返します。
特徴点を全て比較するBFMatcher()をオブジェクト化します。
マッチングの計算に使う距離計算方法を1つ目のパラメータに指定します。デフォルトは cv2.NORM_L2 となっていて、SIFTやSURFといった特徴量記述子に向いています(cv2.NORM_L1 も同様)が、ここではORB(特徴ベクトルの各要素が2値となる特徴量記述子:ORB, BRIEF, BRISK)なのでcv2.NORM_HAMMINGを指定しています。
2つ目のパラメータはブール型変数のcrossCheckで、デフォルト値はfalseに設定されています。Trueに設定するとマッチングのクロスチェックが行われ、両特徴点群の特徴点が互いにベストマッチとなる結果が返されます。
bf.match(des1,des2)で記述子をマッチングします。これをsorted()を使ってラムダで距離をキーとして距離順に並べ変えます。
マッチングの結果はcv2.drawMatches()を使って描画します。2つの画像と特徴点の位置を渡し、最初の25個のマッチングを描きます。この数字は自由に設定できます。どのマッチが描画されるかを指定しないのでNoneにしています。flagsはDEFAULT = 0、DRAW_OVER_OUTIMG = 1、NOT_DRAW_SINGLE_POINTS = 2、DRAW_RICH_KEYPOINTS = 4 となっていて、ここでは2を指定し、シングルポイントを描画しないことにします。
これをdisplay()で表示します。
display(hacker_matches)実際に表示してみます。

結果が表示されました。これはちょっと特徴を掴み切れていない感じですね。
SIFTと割合試験の総当たりマッチング
今度はSIFTを使ってマッチングの検出をしてみます。
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(hacker,None)
kp2, des2 = sift.detectAndCompute(items,None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2, k=2)
good = []
for match1,match2 in matches:
if match1.distance < 0.75*match2.distance:
good.append([match1])
sift_matches = cv2.drawMatchesKnn(hacker,kp1,items,kp2,good,None,flags=2)まず、cv2.xfeatures2d.SIFT_create()でSIFT特徴抽出器を初期化します。
detectAndCompute()を使って先ほどと同様に画像のキーポイントと記述子を見つけて行きます。
同じように特徴点を全て比較するBFMatcher()をオブジェクト化し、今度はBFMatcher.knnMatch()で記述子をマッチングします。これは上位k個のマッチング結果を得るためのもので、ここではk=2として上位2つにしています。
ここで割合試験を行います。goodという空のリストを用意して、この中に条件の良かったものを代入していく作業をして行きます。
for-in文を使ってマッチング結果のmatchesからそれぞれ取り出し、上位1の距離が上位2の距離の75%以下である場合に、goodのリストの中に上位1であるmatch1の値を入れて行きます。ここでは距離が小さいほど良いマッチングを示しています。
今度は、drawMatchesKnn()を使って先ほどと同様にマッチングの結果を描画します。2つの画像と特徴点の位置を渡し、良い結果を得られたgoodのリストを渡しています。あとは同様です。

これをdisplay()で描画していきます。
display(sift_matches)実行するとこうなります。

結果が表示されました。先ほどよりもかなり厳密に特徴を読み取っているのではないでしょうか。
FLANNベースのマッチング
今度はFLANNベースのマッチングをやってみたいと思います。
こちらは辞書型のパラメータを指定してマッチングを描画する複雑な処理となっています。
コードを見て行きましょう。
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(hacker,None)
kp2, des2 = sift.detectAndCompute(items,None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
for i,(match1,match2) in enumerate(matches):
if match1.distance < 0.7*match2.distance:
good.append([match1])
flann_matches = cv2.drawMatchesKnn(hacker,kp1,items,kp2,good,None,flags=0)
display(flann_matches)最初のSIFT特徴抽出器を初期化し、画像のキーポイントと記述子を見つける記述はこれまでと同じです。
次にFLANNのパラメータを設定します。使用する検索アルゴリズムと関連パラメータを指定する2つの辞書型オブジェクトを引数とします。一つ目の辞書はインデックス・パラメータで、2つ目の辞書はサーチパラメータです。checks=50として、インデックス中の木構造を再帰的にたどる回数を指定しています。ここに高い値を設定すれば精度は良くなりますが、処理の時間がもっとかかるようになります。このあたりのパラメータを自分で設定しないといけないのがこちらの処理の複雑なところです。
こちらは総当たりマッチングのBFMatcher()ではなく、cv2.FlannBasedMatcher()にこれらのパラメータを渡します。これをknnMatch()で記述子をマッチングし、上位2個のマッチング結果を得ます。
あとは先ほどのSIFTの処理で行ったことと同じで、良いマッチングを抽出してリストにし、マッチング結果を描画する処理をしています。
実行してみると、こうなります。

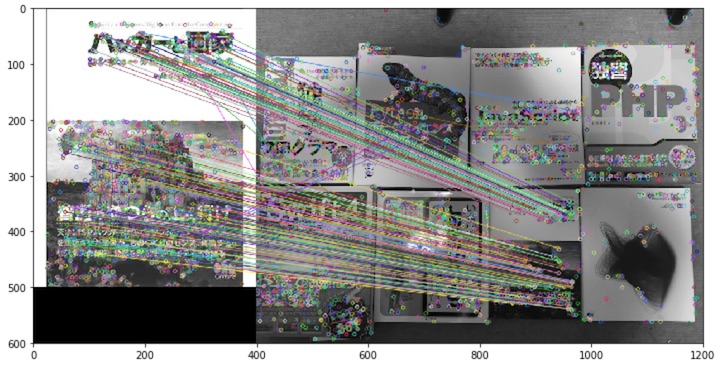
結果が表示されました。
かなりマッチングの精度が上がっているのがわかります。ただ、各ポイントも描画されているので多少わかりづらい面もあります。
これにマッチングがうまくいっている部分とポイントだけ示されている部分とろ区別する為にマスクをかけて描画してみたいと思います。
上のコードを次のように変更してみます。
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(hacker,None)
kp2, des2 = sift.detectAndCompute(items,None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
matchesMask = [[0,0] for i in range(len(matches))]
for i,(match1,match2) in enumerate(matches):
if match1.distance < 0.7*match2.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)
flann_matches = cv2.drawMatchesKnn(hacker,kp1,items,kp2,matches,None,**draw_params)コードの変更部分のみ見て行きましょう。
まずmatchesのデータ数をlen()で調べてmatchsMaskのインデックスにし、全て[0,0]のリストにします。
割合試験のところをenumrate()を使ってインデックスもとり出し、if文の条件が成立した部分のmatchsMask[i]を[1,0]にします。
draw_paramsの部分で、マッチした部分の色を緑、ポイントの部分を赤を指定し、マスクをmatchsMaskに、フラグを0にして辞書型のパラメータを作ります。
あとは、drawMatchesKnn()にこれらを渡して書き換えているだけです。

これをdisplay()で表示してみます。
display(flann_matches)描画するとこうなります。

よりマッチングが明確に表示されたのがわかります。
最後に
OpenCVを使ったPythonでの画像処理について、画像認識について特徴量マッチングを扱ってきました。
静止画像の一部分をテンプレート画像として利用し、それに一致する部分を静止画像から検出するテンプレートマッチングと違い、二枚目の画像中の特徴点を検出してマッチングする方法です。
総当たりマッチングのORB、DIFTとFLANNベースのマッチングを扱ってみました。FLANNベースは精度が上がりますが、精度をさらに上げようとすると処理が遅くなり、またパラメータを調整して渡す必要があるところが難しいようです。

