
ここでは簡単なWebスクレイピングに挑戦してみましょう。入門編ということで、このサイトのトップページを材料に行って行きます。
すでにBeautifulSoupライブラリのインストールは済んでいます。

さっそくPythonでのWebスクレイピングのコードを書いて行きましょう。
Webスクレイピングに挑戦!
Webスクレイピングの対象URLは、https://code-graffiti.com/ とします。記事タイトル一覧を抜き出すことに挑戦してみましょう。
Webスクレイピングのコードを書いてみる
まずライブラリをインポートします。
from bs4 import BeautifulSoup
import requestsBS4とwebデータをやり取りするrequestsをインポートしています。
次は対象のURLを読み込みます。
r = requests.get("https://code-graffiti.com/")
c = r.content
# print(c)requestsライブラリのget()を使ってURLを読み込みます。これをrという変数に入れてオブジェクト化し、contentでデータ化したものを変数cに入れています。
ここで敢えてcをprint()で出力してみると下のようにバイト文字列でサイトのデータが表示されます。(ファイル名web_scraping.pyをAtomで実行)
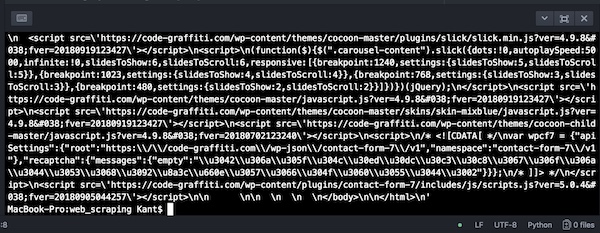
このままでは解読が難しいので、htmlの形で解析します。
soup = BeautifulSoup(c, "html.parser")
# print(soup)BeautifulSoupにcを入れて、”html.parser”というHTML形式で解析して、変数soupに代入します。
これを敢えてprint出力するとこうなります。
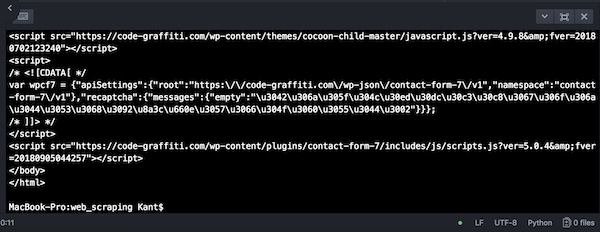
html形式でwebデータが表示されているのがわかります。ブラウザでのソースの表示と同じですね。
ここから目的である記事タイトルの一覧を取得していきます。ソースを確認すると、記事タイトルは<h2>タグで囲まれています。
titles = soup.find_all('h2')
# print(titles)find_all()を使って抽出して行きます。丸括弧の中に(‘h2’)を目的のタグとして指定します。これをtitlesという変数に入れて、試しにprint出力してみましょう。
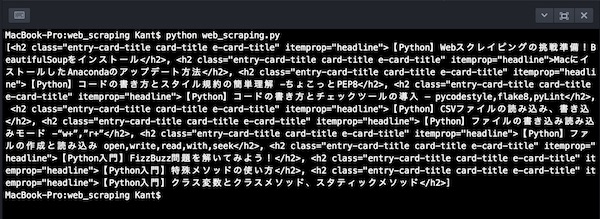
リスト形式で<h2>タグで囲まれたものが全て抽出されています。
この中からタイトル部分のテキストだけ抜き出して表示すれば記事タイトルの一覧が抜きだせることになります。
for title in titles:
print(title.text)リストから値をfor-inループ文で取り出して、textを出力しています。
これらのコードを全て最初からまとめて書くとこうなります。
from bs4 import BeautifulSoup
import requests
r = requests.get("https://code-graffiti.com/")
c = r.content
soup = BeautifulSoup(c, "html.parser")
titles = soup.find_all('h2')
for title in titles:
print(title.text)これを実行してみましょう。
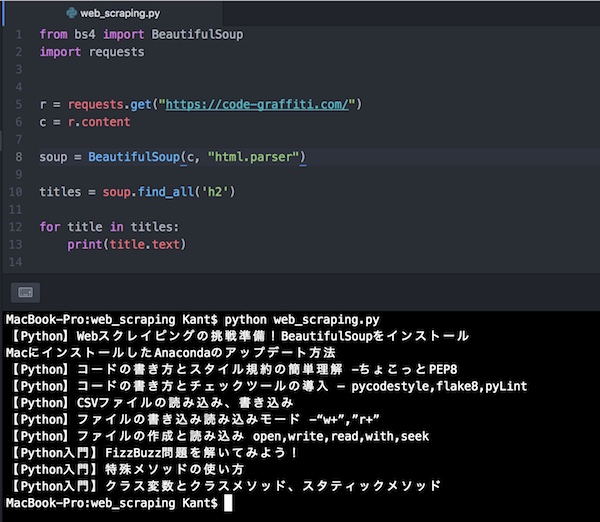
記事タイトルの一覧が取得できました。
少し違うコードの書き方
ほんの少し違う書き方ですが、こちらのコードでも同じ結果が得られます。
from bs4 import BeautifulSoup
import requests
html = requests.get("https://code-graffiti.com/")
soup = BeautifulSoup(html.text, "lxml")
titles = soup.find_all('h2')
for title in titles:
print(title.text)主な違いはsoupのところの記述ですね。getで取得したURLデータをtextで表示するに当たって、”lxml”のを指定しています。ちなみにこれを入れずにsoupをprint出力して見ると、Warningが表示されて、HTMLのparserとして”lxml”を使うのが最適だというようなコメントが表示されます。それにしたがって使っています。あとは上のやり方と同じですね。
さらにWebスクレイピングに挑戦!
タイトル一覧が取得できたので、今度はカテゴリーのタイトルの表示一覧を抜き出して見ることにします。
ここでは、最初にやった方法でコードを書いてみることにします。
from bs4 import BeautifulSoup
import requests
r = requests.get("https://code-graffiti.com/")
c = r.content
soup = BeautifulSoup(c, "html.parser")
categories = soup.find_all('li',{'class': 'cat-item'}) # カテゴリーの指定
for category in categories[0:5]: # リストのインデックスを指定して抜き出す
print(category.text, end="") # 改行を削除して表示今回は<h2>タグだったところをカテゴリーのある場所に変更しないといけません。ページのソースで該当する部分を探すと次のようなタグで始まるところにカテゴリーのタイトルがありました。
<li class=”cat-item cat-item-25″>
ここを利用してfind_allの丸括弧の中を、(‘li’,{‘class’: ‘cat-item’}) という形で書いています。
この部分が他の属性なら、同様の要領で書くことになります。
カテゴリーをリスト表示で抜き出したのですが、このサイトには同じ表記がソースに2回繰り返して出てくることになった(10個)ので、ここでは前半の5つを抜き出すために、リストのインデックスで範囲指定しています。
表示も改行文字が末尾に含まれていたので、endオプションで削除して表示することにしました。
コードを実行するとこうなります。
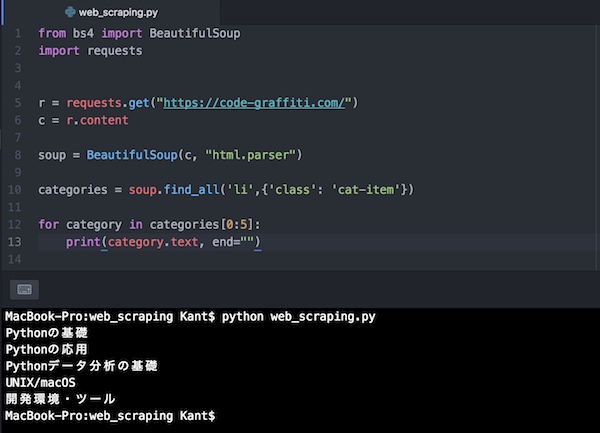
カテゴリーの表示を抜き出すことができました。
こうしてPythonのWebスクレイピングの基本的なやり方を利用するできました。
ここでは入門的なコードを使いましたが、もちろんメソッドは他にもたくさんあります。
もっと発展的なことや、機械学習などのデータ収集など本格的なWebスクレイピングは、また別のところでまとめてやろうと思います。
まとめ
PythonでのWebスクレイピングを、このサイトのトップページの表示を使って簡単なコードでやってみました。
BeautifulSoupやrequestsのライブラリの基本的な使い方をみてきました。get()やffind_all()でURLのデータを取得し、htlm形式に加工し、目的の部分のタグを利用してデータを抽出しました。class属性での抽出の方法にも触れました。
ここでは基本的なWebスクレイピングのみを行いましたが、もっと発展的で、機械学習などのためにデータを抽出する方法などは別の機会にしっかりやりたいと思います。

