
ここではWebスクレイピングについて簡単に学んでみようと思います。
Webスクレイピングは、インターネットからデータ情報を収集する作業です。WebサーバにHTMLなどのWebページを作っている形式のデータを要求し、そのデータを整理して必要な情報を抽出するプログラミングです。
こレから簡単なWebスクレイピングに挑戦してみましょう。ここではその準備を行おうと思います。
はじめてのWebスクレイピング
Webスクレイピングはインターネットのサイトの情報を取り出すわけですが、サイトによってはスクレイピングでのアクセスを禁止しているところもあります。
また、スクレイピングのプログラミングによっては、何度も頻繁にアクセスするようなことがあるので、サーバーの負荷にならないようにアクセスのインターバルに気をつけないといけないこともあります。
他のサイト運営者に迷惑かけないように、ここでは、このサイトのトップページに表示されている投稿記事タイトルをWebスクレイピングで抽出することに挑戦してみようと思います。
このサイトのトップページのURLは https://code-graffiti.com/ です。
サイトのソースコードの確認
サイトのソースをチェックしてみましょう。
ソースを表示するには、サイト上で右クリックして「ページのソースを表示」を選択するか、ブラウザ(Chrome)の表示から「開発/管理」の中のソースを表示や、デベロッパーツールから、サイトのソースを確認します。
こちらはデベロッパーツールの画面です。
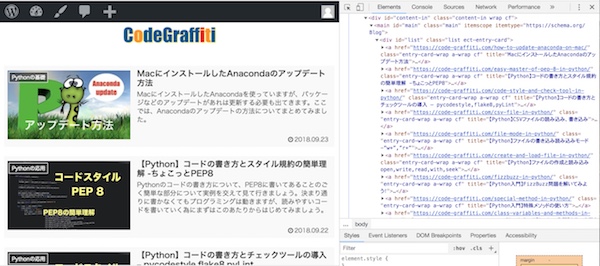
ソースコードを見ていくと、記事のタイトルの一覧はどのタグで表示されているかがわかります。このあたりを手がかりに、データを抽出していくのがWebスクレイピングということになります。
さっそくはじめたいのですが、Webスクレイピングをするにはちょっと準備が必要ですので、そちらを今回はやっておきましょう。
BeautifulSoupのインストール
PythonでWebスクレイピングを行うのに、便利なライブラリがBeautifulSoupです。BeautifulSoupはPythonの標準ライブラリでは無いのでインストールする必要があります。
BeautifulSoupライブラリのインストール
ここではAnacondaの環境を使っているので、ひょっとしたらすでにインストールされているかもしれませんが、BeautifulSoupのインストールはターミナルから次のコマンドでインストールしましょう。
$ conda install beautifulsoup4あるいは、Anaconda NavigatorのEnviromentsからbeautifulsoup4を検索してインストールすることができます。
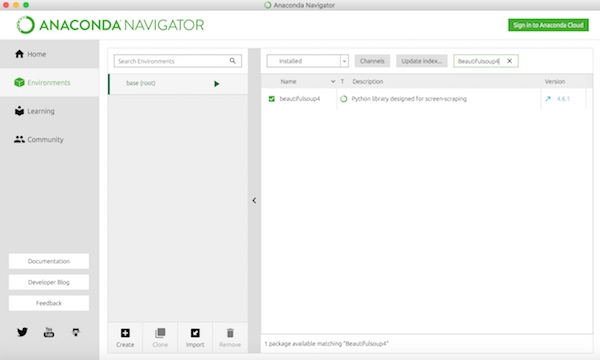
もちろん、ターミナルからpipコマンドでインストールすることもでます。
$ pip install beautifulsoup4インストールはこれで完了。
ターミナルからPython3を起動して、インポートしてみましょう。
from bs4 import BeautifulSoupインポートはこのように入力します。
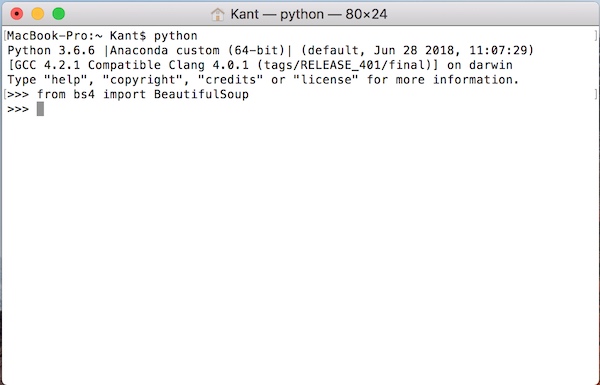
インポートしてエラーが無いので、無事インストールが完了しています。
ちなみにBeautifulSoupのライブラリはBeautifulSoup4ライブラリなので略してBS4と言うこともあります。
requestsライブラリのインストール
同様にして、requestsライブラリもインストールしてみましょう。
requestsモジュールはwebデータのやり取りを行うことができるサードパーティライブラリで、Pythonの標準ライブラリのurllibを使うこともできますが、requestsを使う方がシンプルに書けます。
準備ができたので、次は簡単なWebスクレイピングに挑戦です。
まとめ
Webスクレイピングは、インターネットからデータ情報を収集する作業です。WebサーバにHTMLなどの形式のデータを要求し、そのデータを整理して必要な情報を抽出します。
webページのソースを見ることで、必要なデータをどこから抽出するかの整理をします。
PythonでWebスクレイピングを行うには、便利なサードパッケージライブラリのBeautifulSoupをインストールして利用します。これらを使って、次は簡単なWebスクレイピングに挑戦しましょう。


