
scikit-learnはPythonで機械学習を行うことができるオープンソースのライブラリです。機械学習のアルゴリズムはとてもたくさんあって、scikit-learnでその多くを使えるようになっています。どんなものがあるのか全てに触れることはここでは出来ないので、scikit-learnの公式サイトを参照してください。

ここではscikit-learnの基本的な使い方を公式サイトの中の例にある直線回帰分析を使って簡単に学んでいきます。
Anacondaを使っているなら、scikit-learnはすでにインストールされているのではないかと思いますが、入っていなければターミナルからcondaコマンドやpipコマンドでインストールしましょう。
ここもjupyter notebookを使って学んでいきましょう。
Scikit-learnで直線回帰分析
scikit-learnを使って、直線回帰をやってみましょう。データはscikit-learnの事例の中にあるものをここでは使います。
ライブラリのインポート
まずライブラリのインポートから。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_scoreこれまで扱ってきたNumPy、Pandas、Matplotlibも合わせてscikit-learnもインポートします。データとモデルのライブラリだけでなく、統計量計算のライブラリも入れています。
データのロード
ここではscikit-learnで用意されているデータをload_diabetes()でロードして使っていきます。
diabetes = datasets.load_diabetes() #糖尿病データ
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df.head()これは糖尿病のデータだそうです。これを表示する為にDataFrame()を使って冒頭だけ表示してみます。
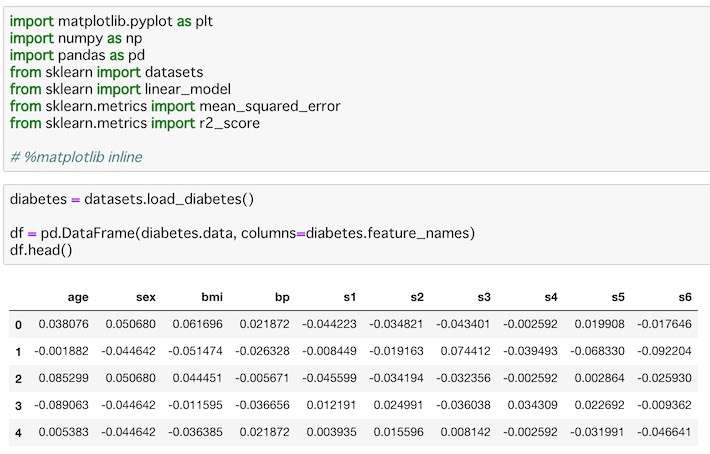
年齢、性別、BMIなどのデータで構成されているのがわかります。
本来ならここでは自分で集めてきたデータのCSVファイルなどを読み込むところになるわけです。
利用するデータを抽出
この中からBMIのデータだけを抜き出して使ってみることにします。
diabetes_X = diabetes.data[:, np.newaxis, 2]
diabetes_Xこれで全体のデータからBMIの値だけ新たに抜き出してデータを作成しています。
(400以上あるデータなので途中まで表示しています)
BMIの部分が抜き出されているのがわかります。
そしてこちらがターゲットデータで、糖尿病の進行度を意味するデータが入っています。
diabetes.target
このBMIの値と糖尿病の進行度合いのデータを使って2つの関係を分析するわけです。
学習データとテストデータに分割
これらのデータをそれぞれ学習用データとテスト用データに分割します。
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# from sklearn import model_selection
# diabetes_X_train, diabetes_X_test, diabetes_y_train, diabetes_y_test = model_selection.train_test_split(diabetes_X, diabetes.target, test_size=0.045)データは、データの残り20個のところで区切って、学習用とテスト用に分けています。
最後2行にコメントアウトしている部分がありますが、ライブラリをインポートしたら、これらのコードはこの1行でも書けるということを示しました。本来はtest_sizeは0.2くらいが良いとされていますが、上の例の数になるように合わせました。
回帰モデルを適用する
直線回帰分析を行っていきます。
regr = linear_model.LinearRegression()
regr.fit(diabetes_X_train, diabetes_y_train)
#regr.score(diabetes_X_test, diabetes_y_test)直線回帰のモデルを使ってオブジェクトにし、fit()を使って学習用データを学習させます。score()でどれくらいの精度のモデルであるかをテストデータで確認出来ます。
予測値を計算
これで予測値を出していきます。
diabetes_y_pred = regr.predict(diabetes_X_test)
print('係数: ', regr.coef_)
print("標準偏差: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
print('スコア: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))predict()にBMIのテストデータを入れて予測値を計算します。詳細はここでは説明しませんが、統計量を表示するコードも書いています。
グラフに描画する
あとはグラフにしていくだけです。
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()scatter()を使ってテストデータの分布を黒色で示しています。予測値を青色の直線で示しています。特に目盛りは記入せずに、show()で表示します。
結果はこうなります。
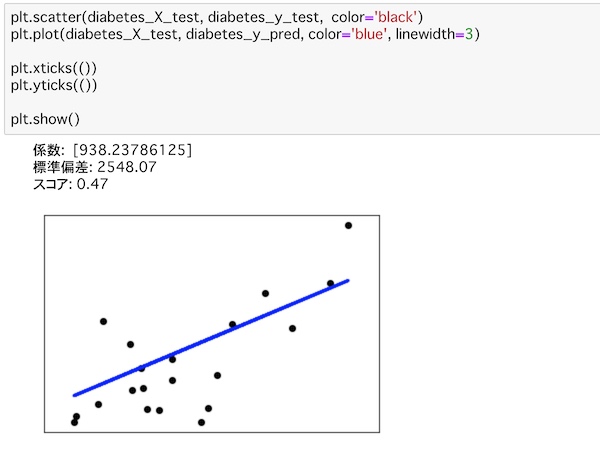
あまり精度の良い分析ではなかったようですね。BMIと糖尿病の進行との関係はなんとなくはあるようにも見えますが、強くは関連していないようです。
全体のコードを見る(再掲)
全体のコードを余計な部分を取り除いて、もう一度まとめておきます。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
diabetes = datasets.load_diabetes()
diabetes_X = diabetes.data[:, np.newaxis, 2]
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
regr = linear_model.LinearRegression()
regr.fit(diabetes_X_train, diabetes_y_train)
regr.score(diabetes_X_test, diabetes_y_test)
diabetes_y_pred = regr.predict(diabetes_X_test)
print('係数: ', regr.coef_)
print("標準偏差: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
print('スコア: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()回帰分析の概念がわからない人もいるとは思いますが、そのあたりは統計などの学習が必要になります。
最後に
scikit-learnはPythonで機械学習を行うことができるオープンソースのライブラリで、ここでは直線回帰のアルゴリズムを使って使い方の流れをサラッと見てきました。
機械学習のアルゴリズムはたくさんあるので、scikit-learnの公式サイトの中を色々覗いて見るのもいいと思います。
さらに詳しいところは別のところで扱おうと思います。

