
Pandasでデータを集約するには、sum()やmean()を使えば全体の様子を掴むことができます。
ですが、より詳細にデータを集約するには、インデックスや列に条件をつけて絞り込む必要があります。この操作をするにはgroupby()を使うことで実現できます。group by は「グループ別」という意味ですね。
ここでは、このgroupby()の使い方を簡単に見て行こうと思います。
groupby()を使う
jupyter notebookを起動して、まずここで扱うデータを作って起きましょう。
import pandas as pd
data = {'Prefecture': ['Tokyo', 'Tokyo', 'Osaka', 'Osaka', 'Fukuoka', 'Fukuoka'],
'Area': ['Aoyama', 'Shibuya', 'Sakai', 'Suita', 'Hakata', 'Kokura'],
'Point': [150, 120, 200, 100, 230, 180]}pandasをインポートして、辞書型のデータを用意します。適当に作ったデータですので、特に意味はありませんのでご注意を。
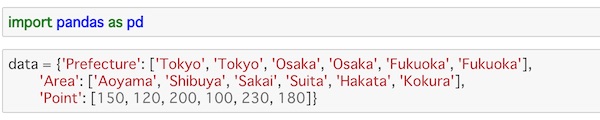
このデータを使ってDataFrameを作ります。
df = pd.DataFrame(data)次のように表示されます。
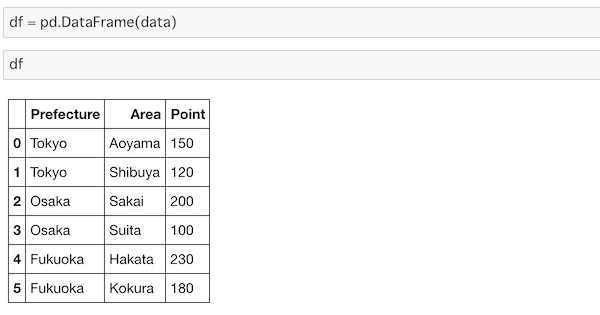
これをgroupby()を使ってデータの集約をして行きます。列名のPrefectureに基づいて、行をグループ化します。
df.groupby('Prefecture')
グループ化したオブジェクトができました。
これをby_prefという変数に代入してメソッドを呼び出していきましょう。
mean(), sum(), std()
まずデータの平均を出してみます。
by_pref = df.groupby('Prefecture')
by_pref.mean()平均はmean()で求められます。
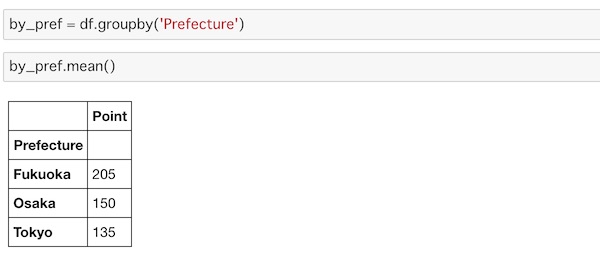
それぞれ2つのデータが入っていましたが、そのそれぞれの平均が求められています。
次は合計、標準偏差です。
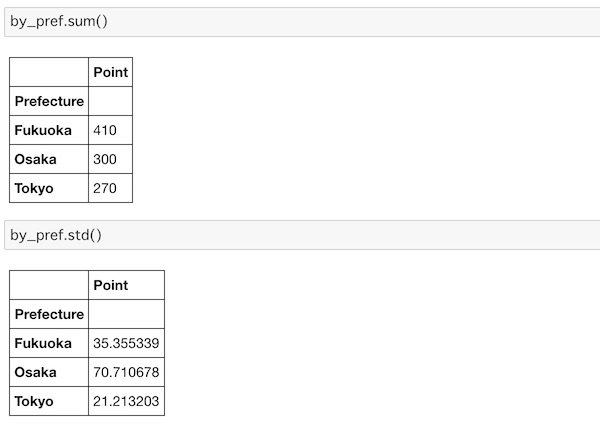
by_pref.sum()
by_pref.std()合計はsum()、標準偏差はstd()で求めます。
locでラベルを指定
次は、locを使って行ラベルを指定し、合計を出してみます。
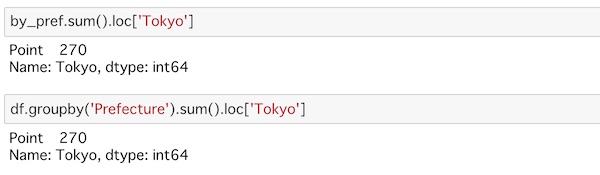
by_pref.sum().loc['Tokyo']
df.groupby('Prefecture').sum().loc['Tokyo']Tokyoの合計を出します。dfのまま集約もしてみました。
count()
それぞれのデータ数を数えるにはcount()を使います。
df.groupby('Prefecture').count()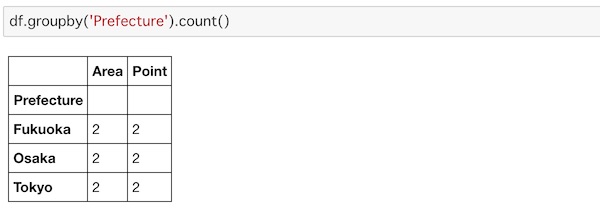
Prefectureを基準にしてそれぞれのデータ数がカウントされてます。
max(), min()
それぞれの最大値、最小値を求めます。
df.groupby('Prefecture').max()
df.groupby('Prefecture').min()最大値、最小値はmax()、min()を使います。
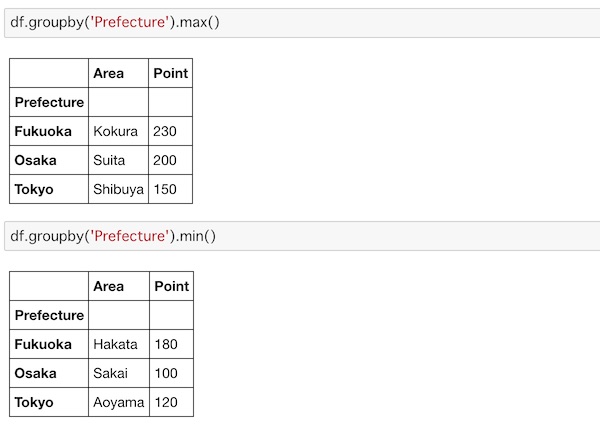
各データの最大値、最小値が得られています。
describe()で要約統計量を取得
要約統計量を求めるにはdescribe()を使います。
df.groupby('Prefecture').describe()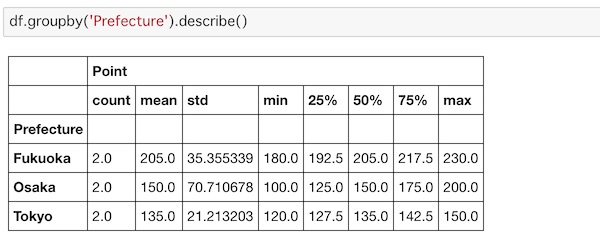
統計量の意味を復習しておくと、それぞれデータ個数、平均、標準偏差、最小値、第一四分位数、第二四分位数、第三四分位数、最大値を意味します。
データの行と列とを入れ替えるにはtranspose()を使います。
df.groupby('Prefecture').describe().transpose()![]()
行ラベルを指定して統計量を取得することもできます。
df.groupby('Prefecture').describe().transpose()['Tokyo']![]()
Tokyoのデータの統計量が取得できました。
最後に
ここではPythonの拡張モジュールのPandasを使って、groupby()の操作を見てきました。
そのままsum()やmean()を使えばデータの全体の様子を掴むことができますが、groupby()を通すことでインデックスや列に条件をつけてデータを詳細に絞り込むことができます。

