
PythonのPandasを扱っていて、これまで欠損値というものが何度か出てきました。
データに欠落する部分が出てきた時には、Pandasが自動的に欠損値であること示すようにそこに埋め込まれます。
ここでは、このデータの欠落部分をデータ全体から削除したり、欠損値の代わりに記入するなどの操作をするメソッドを簡単に見ていきましょう。
Pandasの欠損値の除外と代入操作
Pandasで欠損値を処理するメソッドを見て行きましょう。Pandasでは欠損値はnp.nanで与えることができます。
まず欠損値を含むDataFrameを作っておきましょう。
import numpy as np
import pandas as pd
d = {'x': [1, 2, np.nan], 'y': [4, np.nan, np.nan], 'z': [7, 8, 9]}
df = pd.DataFrame(d)NumPyとPandasをインポートします。DataFrameは辞書型のデータから作ることもできるので、dという辞書データを用意しました。値の中に欠損値であるnp.nanを入れています。
実行するとこうなります。
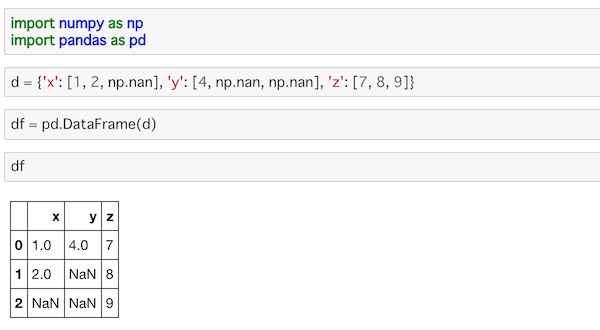
辞書データのキーをカラム(column)にしたDataFrameが出力されました。
欠損値の削除 – dropna()
欠損値の削除にはdropna()を使います。
df.dropna(axis=1)axis=1を指定して欠損値のあるデータを除外したものを取り出します。
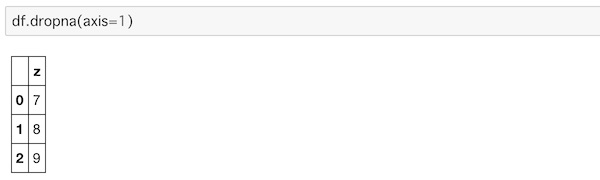
x、y列にはNaNがあるので削除され、z列のデータが表示されました。
axisを指定しない場合は行側のデータからNaNの値を削除します。これはちなみにaxis=0がデフォルトとなっていることを意味します。
df.dropna()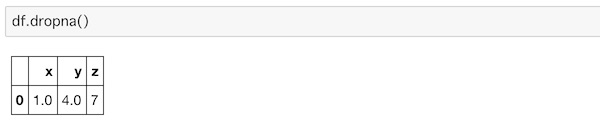
dropna()にthreshを使って閾値を指定することができます。これを指定すると、指定した数を超えるNaNを持った行を削除したデータを取り出すことができます。
df.dropna(thresh=2)2つ以上NaNがある行データを削除します。
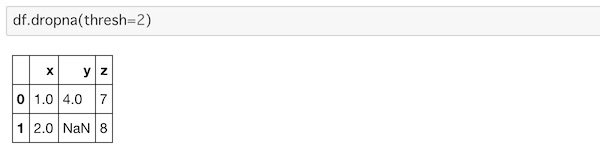
一番したの行にNaNが2つ入っていたので削除されているのがわかります。
欠損値を置き換える – fillna()
今度は欠損値の部分に値を入れて置き換える操作をします。
ここで一度、dfを表示し直します。
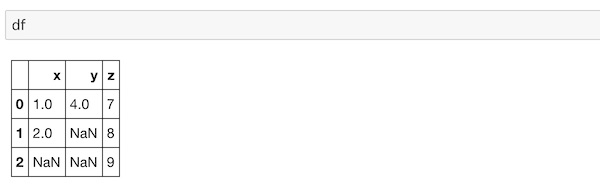
このNaNの部分に任意の値を入れます。
値を入れるにはfillna()にvalueを指定することで可能になります。
df.fillna(value='some value')‘some value’でNaNを埋めることになります。

欠損値の部分が埋められているのがわかります。
欠損値を埋めるのに、すでにあるデータの平均を使うこともあります。
ここではx列の平均を欠損値に入れてみることにします。
df['x'].fillna(value=df['x'].mean())平均はmean()メソッドを使うことで取得できます。
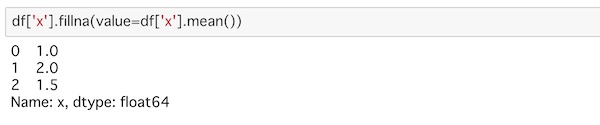
x列のNaNの部分に平均値が記入されているのがわかります。
最後に
ここではPythonの拡張モジュールのPandasを使って、欠損値を処理する操作を見てきました。
欠損値をデータ全体から削除したり、代わりの値で置き換えるメソッドをしっかり理解しましょう。

