
OpenCVを使ったPythonでの画像処理について、ここでは静止画から物体を認識をする方法を扱います。
ここではテンプレートマッチングという方法を見ていきましょう。
静止画像からテンプレート画像と一致する部分を検出するのがテンプレートマッチングで柔軟性はありませんが、とても手軽な手法と言われています。
テンプレート画像を被検出画像上でスライドさせていき、両画像の領域を比較していくことで、類似度の高い領域を検出して物体を認識するという方法です。
被検出画像とテンプレート画像
ここではjupyter notebookを使ってテンプレートマッチングを見ていきましょう。
まず、被検出画像とテンプレート画像を用意して読み込んでみます。
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineOpenCVをはじめとして、各種ライブラリーをインポートしています。このあたりはもうお決まりのインポートです。
full_img = cv2.imread('images/dog.jpg')
full_img = cv2.cvtColor(full_img, cv2.COLOR_BGR2RGB)
plt.imshow(full_img)imread()を使って画像を読み込み、cvtColor()でBGRからRGBにカラー変換して画像を表示しています。このあたりも画像処理ではおなじみの処理です。
表示するとこうなります。
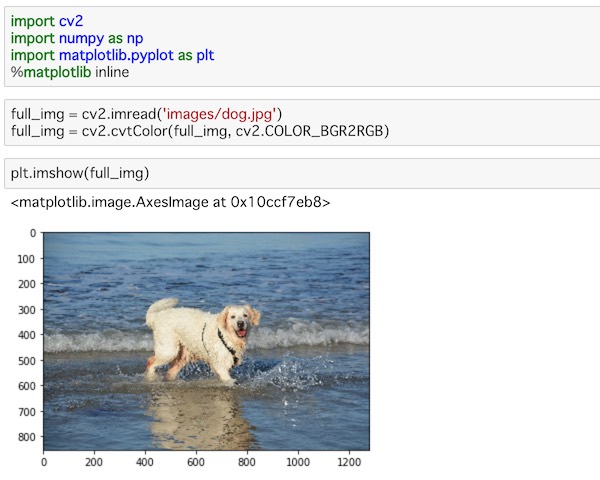
こちらが元の画像で、被検出画像となります。
次はテンプレート画像を読み込みます。
face_img = cv2.imread('images/dog-face.jpg')
face_img = cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB)
plt.imshow(face_img)こちらも同様の処理です。

こちらがテンプレート画像になります。これは元の画像の犬の顔の部分を切り抜いたものです。目盛りを見ると大きさがわかると思います。サイズを確認すると以下のようになります。
height, width,channels = face_img.shape
width
height
このテンプレート画像が元の画像のどこにあるのか検出するのがテンプレートマッチングです。
テンプレートマッチングの方法
では、この2つの画像を使って、テンプレートマッチングをやっていきましょう。
full_img = cv2.imread('images/dog.jpg')
full_img = cv2.cvtColor(full_img, cv2.COLOR_BGR2RGB)
face_img = cv2.imread('images/dog-face.jpg')
face_img = cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB)
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR','cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']再度、被検出画像とテンプレート画像を読み込むコードも表記してみました。先ほどと同じコードです。画像を読み込み、カラーコードの変換をしています。
変数methodsにリストを与えています。これは比較する時の手法のリストです。テンプレートマッチングはテンプレートを被検出画像全体に対してスライドさせて、それと重なる幅と高さの領域を比較するわけですが、この比較する手法の指定がこれにあたります。
それぞれの細かい数学的な意味はここでは触れませんが、関心のある方はこちらの記事の数式を参考にしてください。

6つのメソッドを利用することになります。
この手法を使って、テンプレートマッチングを行っていきます。

次のコードで全てのmethodsを使って検出しています。
for m in methods:
full_copy = full_img.copy()
method = eval(m)
res = cv2.matchTemplate(full_copy,face_img,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + width, top_left[1] + height)
cv2.rectangle(full_copy,top_left, bottom_right, 255, 10)
plt.subplot(121)
plt.imshow(res)
plt.title('Result of Template Matching')
plt.subplot(122)
plt.imshow(full_copy)
plt.title('Detected Point')
plt.suptitle(m)
plt.show()
print('\n')
print('\n')ちょっと長いですが、上から順番に見ていきましょう。
このコード全体は、for-in 文のループ処理を使って、テンプレートマッチングに使うmethodsを1つずつ取り出して処理を行っています。
copy()を使って、被検出画像を複製し、これを処理に使っていきます。
methodsからとり出したそれぞれの手法mを、eval()を使って引数を式として評価させます。これで比較メソッドで計算ができることになります。
matchTemplate()に元画像(コピー)とテンプレート画像、比較するメソッドを与えています。これでマッチングの処理を行っています。テンプレート画像をメソッドに応じてスライドさせながら、注目領域を比較している操作になります。
minMaxLoc() を使って、マッチング操作の類似度の最大値、最小値となる画素とその位置を調べています。
テンプレート画像に最も似ている領域を表す矩形の左上の画素が類似度が最大となります。その画素の位置、領域のサイズの高さの幅を示していることになります。
ただし次の部分については注意が必要です。
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_locこの部分に関しては、この2つのメソッドがテンプレートマッチングの結果の値が小さければ小さいほどテンプレート画像と注目領域が似ていることを示しているので、それについてのメソッド毎の処理の区別をしています。
bottom_rightの部分で、基準となる座標に幅と高さを加えることで、四角形の右下の座標を与えています。
rectangle()で四角形を被検出画像(コピー)に描いています。画像と座標を指定し、線の色と太さを与えています。
あとはsubplot()とimshow()を使ってsubplot(121)で左側、subplot(122)で右側にそれぞれテンプレートマッチングの結果と検出位置を表示させています。
コードを実行すると次のように表示されます。
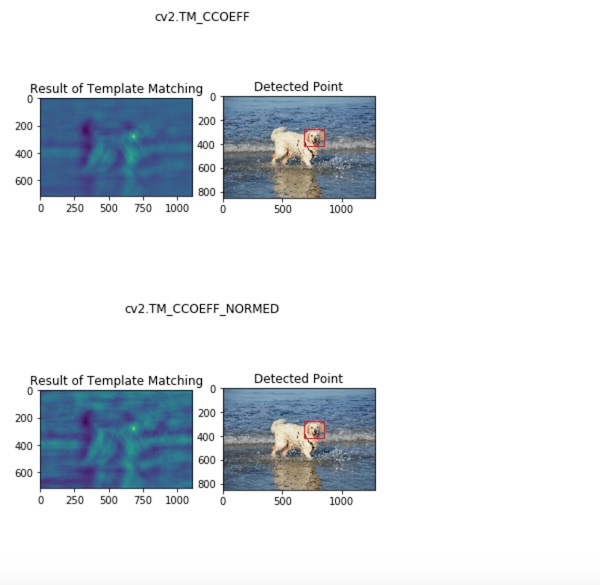
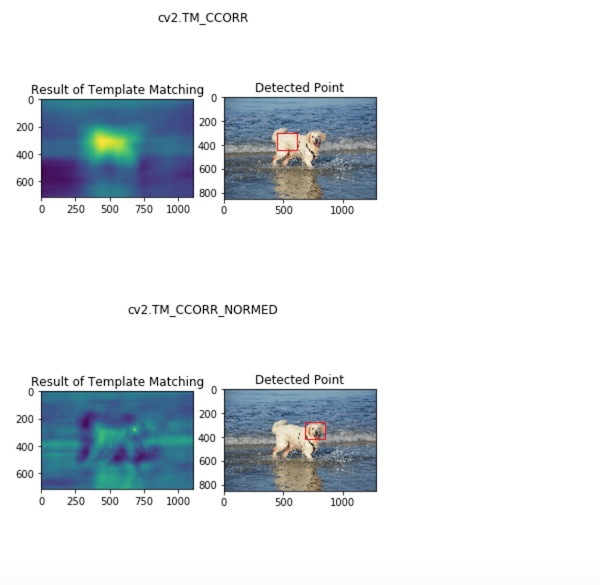
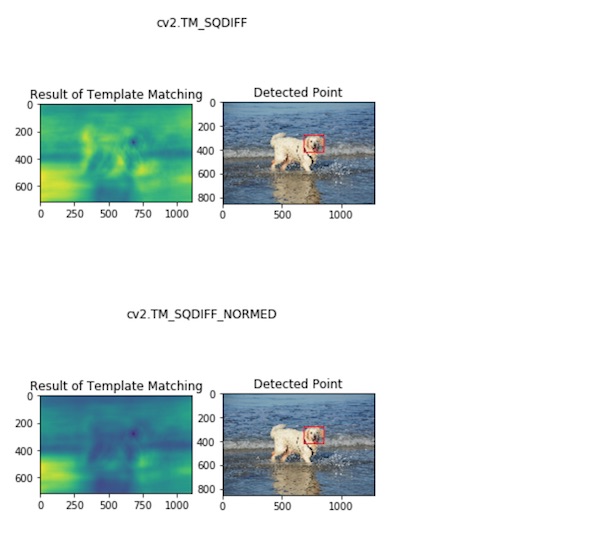
以上、結果が出ました。元になる画像に対してテンプレートとして与えた犬の頭の部分について認識されているのがわかります。
右側の画像の赤い四角で囲まれた部分が認識された部分です。左側の画像ではヒートマップで類似度の高い部分が示されているのがわかります。
ただし、cv2.TM_CCORRのメソッドで処理したものについては、赤い四角がズレてしまっているので、思ったような結果が得られなかったということになります。
最後に
ここでは、OpenCVを使ったPythonでの画像処理について、静止画から物体を認識をする方法を扱いました。
テンプレートマッチングという方法を扱いましたが、これはテンプレート画像を被検出画像全体に対してスライドさせて、それと重なる幅と高さの領域を比較し、類似度の高い部分に注目して物体を認識する方法です。
柔軟性はありませんが、手軽な手法がテンプレートマッチングの物体検出です。

