
Pythonに画像処理ライブラリのOpenCVを使って画像の読み込みや色の変換をおこなってきましたが、画像処理といえば複数の画像を合成したり重ねたりすることの方が身近な処理です。
ここでは2つの画像を用意して、合成したり重ねたりする方法を見ていきたいと思います。
画像の合成 – addWeighted()
2つの画像を合成する方法を簡単に見て行きましょう。
次の2つの画像を用意してみました。
camera.jpg

ok.png

この画像を使ってここでは画像処理をしていきます。
ライブラリのインポートと画像の読み込み
まず、jupyter notebookを使って、各種ライブラリをインポートします。
import cv2
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inlineあとで使うので、OpenCV以外にもまとめてインポートしました。
先ほど用意した画像を読み込んでいきます。
img1 = cv2.imread('images/camera.jpg')
img2 = cv2.imread('images/ok.png')作業ディレクトリにこれまでと同様にimagesフォルダを用意して、そこに2つの画像が入っています。これをcv2.imread()で読み込み、それぞれimg1、img2に渡します。
img1.shape
img2.shapeshapeを使って、画像のサイズを見ておきます。
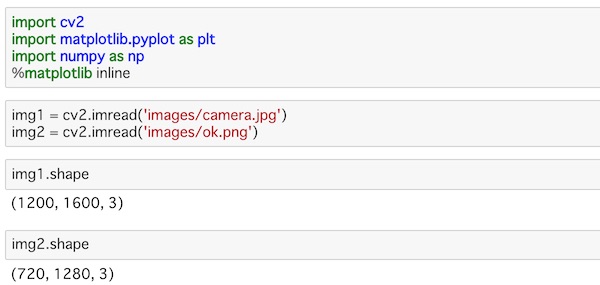
それぞれの画像サイズがわかりました。
画像のカラー変換
この画像はこのままではBGR形式で読み込まれているので、RGB形式に変換します。
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)それぞれの画像をcv2.cvtColor()を使ってcv2.COLOR_BGR2RGBでカラー変換しています。

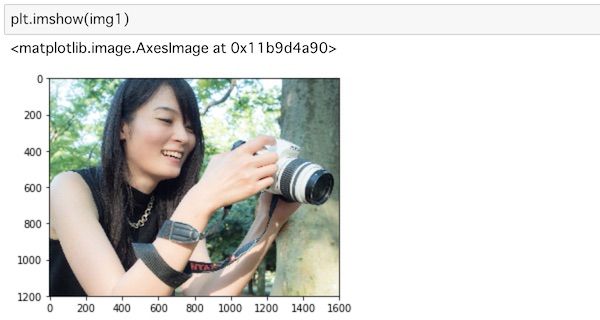
画像を表示してみます。
plt.imshow(img1)
plt.imshow(img2)
plt.imshow()でそれぞれの画像を表示します。

resize()で画像の大きさを揃える
OpenCVで画像の合成をするには、画像の大きさを揃えないとエラーになるので、サイズを揃えず必要があります。
img1 =cv2.resize(img1,(600,800))
img2 =cv2.resize(img2,(600,800))
plt.imshow(img1)
plt.imshow(img2)cv2.resize()を使って2つの画像を同じ大きさに変換しています。
imshow()で表示してみます。


同じ大きさに変換されているのがわかります。
addWeighted()で合成
この2つの画像を合成して行きます。それにはaddWeighted()を使います。
画像の合成は次のような式で計算されます。
img1∗α+img2∗β+γ
blended = cv2.addWeighted(src1=img1,alpha=0.7,src2=img2,beta=0.3,gamma=0)
plt.imshow(blended)addWeighted()を使って画像を合成しています。src1、src2はそれぞれの画像を指定します。alphaは1つ目の画像の重なりの重み、betaは2つ目の画像の重みでそれぞれ透明度のような扱いです。gammaは2つの画像に加算される重みで全体の明度のような扱いです。
実行するとこうなります。

2つの画像が合成されているのがわかります。
画像を重ねる
今度はこの2つの画像を簡単に重ねてみることにします。ここでは大小2つの画像にして重ねてみます。
再度、画像を読み込み直します。
img1 = cv2.imread('images/camera.jpg')
img2 = cv2.imread('images/ok.png')
img2 =cv2.resize(img2,(600,600))
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
large_img = img1
small_img = img2img2を読み込んだら、resizeで画像を小さくしています。img1、img2をそれぞれlarge_img、small_imgとしました。
ここで、画像を重ねる位置の基準としてオフセットの位置を指定しておきます。
x_offset=0
y_offset=0これは画像の左上の角の位置になります。
このオフセットを使って、大きい画像の上に小さい画像を重ねてみましょう。
large_img[y_offset:y_offset+small_img.shape[0], x_offset:x_offset+small_img.shape[1]] = small_img大きい画像データに小さい画像データを代入する形になっています。大きい画像データにオフセットを指定して、小さい画像データを代入する部分を指定することになっています。コロンを使って範囲指定です。オフセットの0の位置から、小さい画像の縦横のサイズまでの範囲を指定しています。x軸とy軸のそれぞれのオフセットとの関係に注意です。shapeで取り出したサイズは第1項が縦のサイズ、第2項が横のサイズになります。
大きい画像の左上の角から、縦600px、横600pxの部分が小さい画像となるということを意味しています。
画像を表示してみましょう。
plt.imshow(large_img)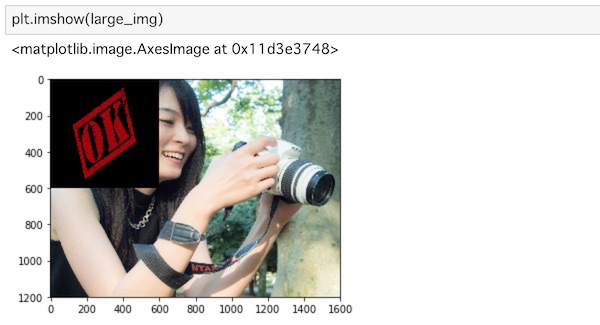
画像が重ねられて表示されているのがわかります。
異なるサイズの画像の合成
ここまでは、同じサイズの画像の合成と異なるサイズの画像を重ねる作業をやってきました。
ここではこれらの応用として、異なるサイズの画像の合成をやっていきたいと思います。
再度、画像を読み込み直します。
img1 = cv2.imread('images/camera.jpg')
img2 = cv2.imread('images/ok.png')
img2 =cv2.resize(img2,(600,600))
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
large_img = img1
small_img = img2関心領域(ROI)を作成する
ここで関心領域を作成します。関心領域とはROIと書き、Region of Interestの略で、対象領域などとも言います。
ここでは、大きいサイズの画像の上に、小さい画像を乗せて合成するという作業をしますので、その対象部分の画像を作成します。
大きい画像のimg1のサイズは次のようになります。
img1.shape
img2はresize()で(600, 600)にしています。この大きさをimg1の画像でROIを作成します。下の画像のようにimg1の右下の部分を関心領域として作成してみます。

ROIを作る為のオフセットの位置は次のように表すことができます。
x_offset=1600-600
y_offset=1200-600この位置から、img1のROIの領域を作るには、次のコードで示すことができます。
rows,cols,channels = img2.shape
roi = img1[y_offset:1200,x_offset:1600]img2の形を取り出すコードを書いていますが、数値自体はもうすでにわかりますね。img1のROIの領域をroiとして作成すにのに、上で示したオフセットから範囲指定を使って画像の右下の位置までを取り出しているのがわかります。
作成したROIを表示してみます。
plt.imshow(roi)imshow()を使ってroiを表示します。

指定した部分が切り取られて表示されているのがわかります。
マスクを作る
そのまま画像を合成してもいいのですが、画像を単純に足し算すると色が変わってしまい、ブレンドをすると画像が透けたようになってしまうので、そのままの色合いで合成させる為にマスクを作っていきます。
img2を使ってマスクを作成して行きます。逆マスクも作ります。
img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
img2gray.shape
plt.imshow(img2gray,cmap='gray')img2をグレースケールに変換してimg2grayとしています。
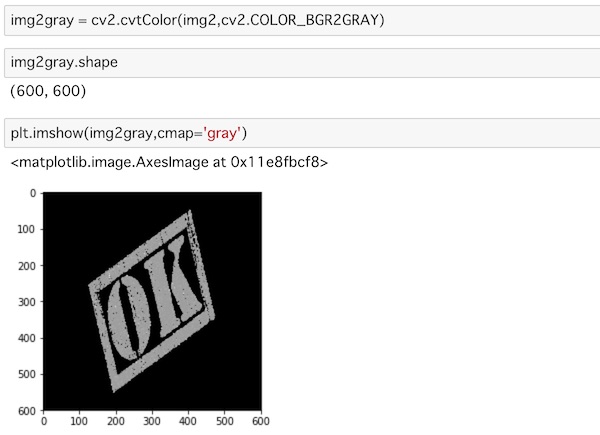
これに対して、逆マスクを作ります。
mask_inv = cv2.bitwise_not(img2gray)
mask_inv.shape
plt.imshow(mask_inv,cmap='gray')グレースケールにしたマスクをbitwise_not()を使って逆マスクにしています。(Bitwise Operations についてはこちらも参考にしてください)
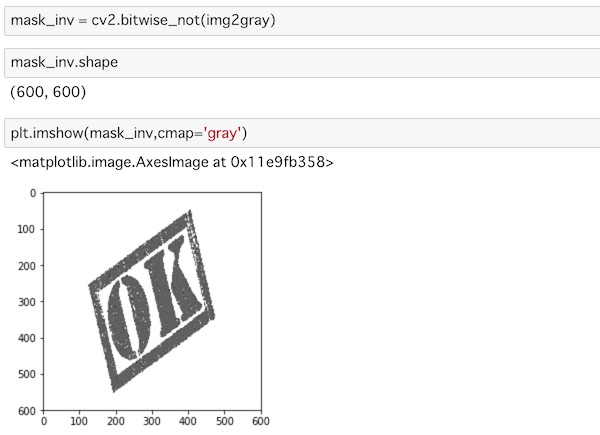
マスクを3カラーチャンネルに変換
img2の変換をもう少しやっておきます。
白いバッググラウンドを作って、それを上で作った逆マスクに出力してみます。
white_background = np.full(img2.shape, 255, dtype=np.uint8)
bk = cv2.bitwise_or(white_background, white_background, mask=mask_inv)
bk.shape
plt.imshow(bk)img2.shapeの配列データを255で埋めて白い画像データを作ります。それをbitwise_or()を使って逆マスクに出力します。
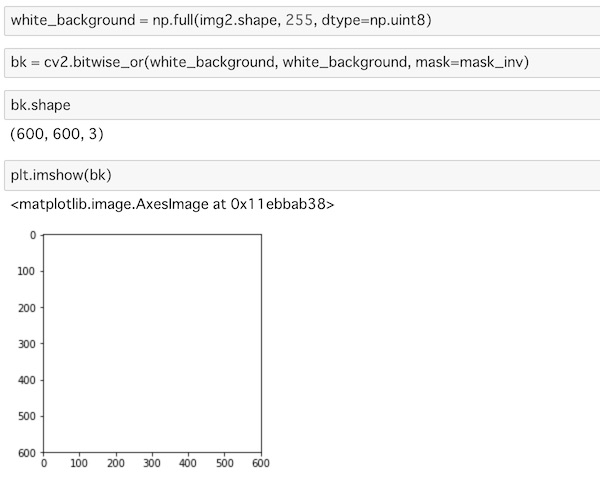
これは白い背景画像がimg2の逆マスクに出力された形になっています。
元の画像をマスクに出力する
同様に、img2の元の画像を逆マスクに出力してみます。
逆マスクを再度表示してみます。
plt.imshow(mask_inv,cmap='gray')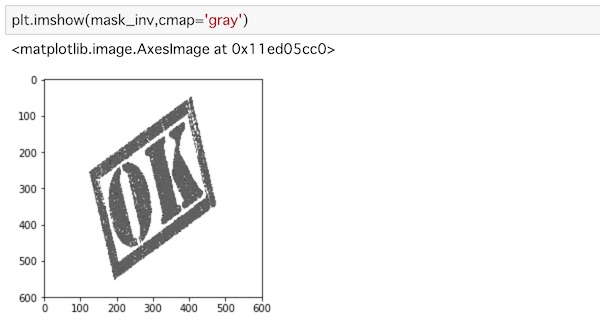
bitwise_or()を使って、元画像のimg2を逆マスクに出力してみます。
fg = cv2.bitwise_or(img2, img2, mask=mask_inv)
plt.imshow(fg)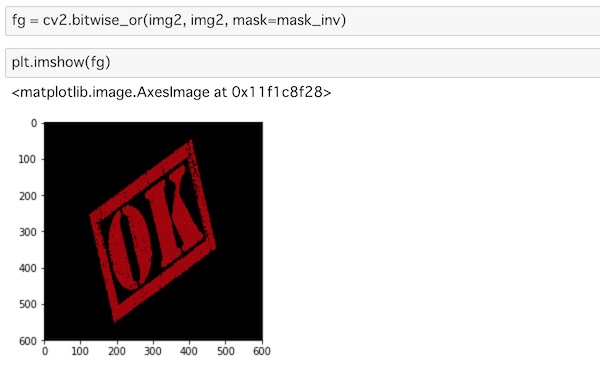
ROIとマスクを合成
これで、指定した範囲の画像のROIと上に合成するマスクが完成しました。
roi、fgで作ったオブジェクトがそれぞれ当てはまります。
bitwise_or()を使ってroiの上にfgを乗せて合成します。
final_roi = cv2.bitwise_or(roi,fg)
plt.imshow(final_roi)表示するとこうなります。
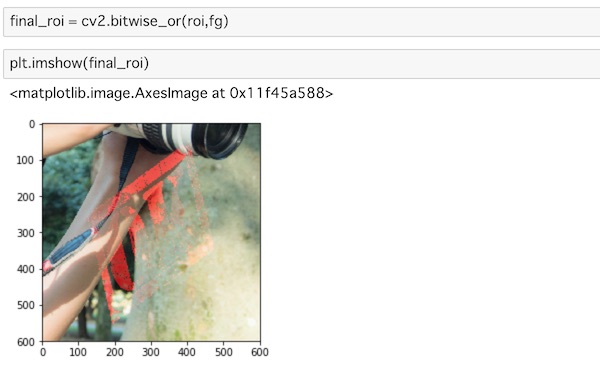
ROIにマスクがされているのがわかります。
画像の残りの部分を追加する
合成された部分が完成したので、残りの画像を追加して全体を表示します。
large_img = img1
small_img = final_roi
large_img[y_offset:y_offset+small_img.shape[0], x_offset:x_offset+small_img.shape[1]] = small_img
plt.imshow(large_img)img1をlarge_img、先ほど作ったfinal_roiをsmall_imgとして合成します。
large_imgのオフセットの位置からsmall_imgのサイズを範囲してすると、それはROIの部分ですから、そこにsmall_imgを代入すれば、合成されたlarge_imgが出来上がります。
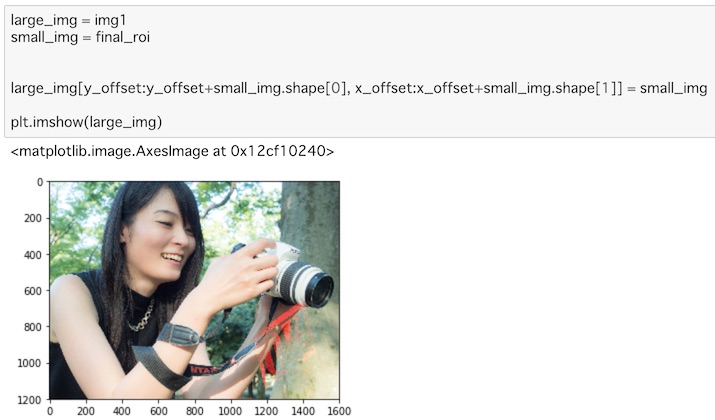
画像の右下にマスクされているのがわかります。(色合いが悪かったのでちょっと見えにくい画像になってしまいました)
最後に
Pythonに画像処理ライブラリのOpenCVを使って、ここでは2つの画像を合成したり重ねたりする方法を見てきました。
イメージの合成はこちらのドキュメントも参考にしましょう。

bitwiseの計算で、AND、OR、NOT、XORの論理演算の意味を画像の合成と合わせてこちらに簡単にまとめておきました。

