
Pandasはデータを参照するコードを使って入力と出力を扱うことができます。
pd.read_メソッドを使ってさまざまな種類のファイルを読み出すことができます。
ここでは次の4つの一般的なデータ型を見ていきたいと思います。
- CSV
- Excel
- HTML
- SQL
ライブラリのインストールと読み込みデータの準備
データの読み込みを扱うにはターミナルから次のライブラリをインストールする必要があります。
$ conda install sqlalchemy
$ conda install lxml
$ conda install html5lib
$ conda install BeautifulSoup4Anacondaをインストールしていれば、おそらくすでに入っているかもしれません。入っていなければ、上記のコマンドかpipを使ってインストールしましょう。
では、データの読み込みの準備をしていきます。
まずPandasのライブラリをインポートしておきましょう。
import numpy as np
import pandas as pd読み込み用のデータファイルとして次のようなデータを持つCSVファイルを用意します。
a,b,c,d
0,1,2,3
4,5,6,7
8,9,10,11
12,13,14,15ファイル名をexample.csvとしておきます。
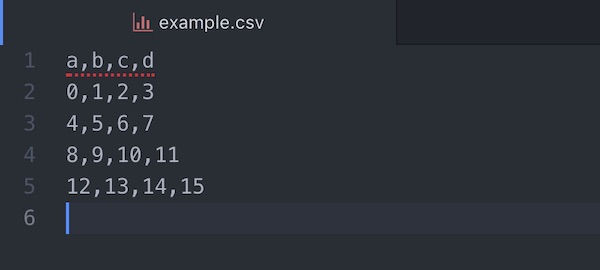
このexample.csv ファイルを作って、現在と同じ作業ディレクトリに配置して操作を進めていきます。
CSVファイルの読み込み
CSVファイルを読み込むには、read_csv()を使います。これにファイル名を指定して読み込みます。
先ほど作ったCSVファイルを読み込んでみましょう。
pd.read_csv('example.csv')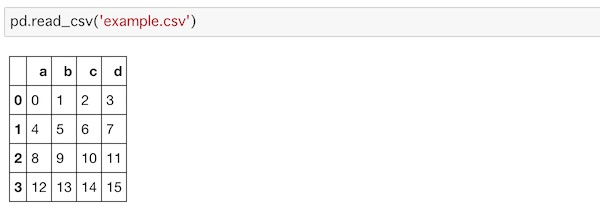
CSVファイルを呼び出すことができました。
これを新たなCSVファイルに書き込むには、to_csv()に新ファイル名を指定して作ることができます。
df = pd.read_csv('example.csv')
df.to_csv('my_example.csv',index=False)読み込んだデータをdfにいれて、to_csv()でファイルを作成します。indexを新たに作る必要は無いのでFalseにしています。
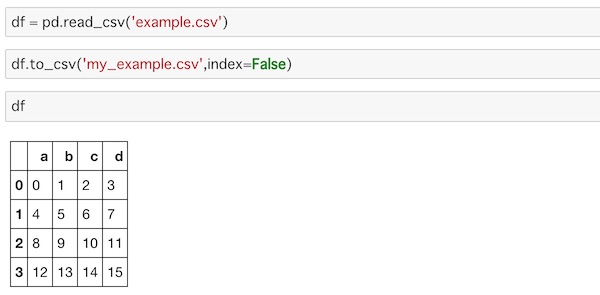
新たにファイルができました。同じ作業フォルダにファイルが作成しているはずです。
Excelファイルの読み込み
次はExcelファイルの読み込みです。上のCSVファイルと同じものをExcelファイルで同じ作業フォルダに作っておきましょう。ここでは、Excel_Sample.xlsxファイルと名前をつけて起きます。
Excelファイルを読み込むには、read_excel()を使います。用意したファイルを読み込んでみましょう。
pd.read_excel('Excel_Sample.xlsx',sheet_name='Sheet1')Sheet_nameを指定していますが、CSVとやってることは同じ要領です。

これも同様に、to_excel()を使って次のようなコードで新しいファイルに書き込むことができます。
df.to_excel('my_Excel_Sample.xlsx',sheet_name='Sheet1')同じ作業ディレクトリにファイルが作成されるはずです。
ExcelデータをPandasで読み込むことで注意が必要なことは、こういったプレーンなデータのみを扱う場合のみということです。マクロの関数が入ったり、画像が埋め込まれたExcelファイルは読み込むことができません。クラッシュすることがあります。
HTMLの読み込み
次はHTMLを読み込みます。read_html()を使いますが、これはwebページの中の表(table)を読むメソッドです。
ここでは試しにウィキペディアの「ベストセラー作家の一覧」を読み込んでみます。
read_html()にURLを渡します。
data = pd.read_html('https://ja.wikipedia.org/wiki/%E3%83%99%E3%82%B9%E3%83%88%E3%82%BB%E3%83%A9%E3%83%BC%E4%BD%9C%E5%AE%B6%E3%81%AE%E4%B8%80%E8%A6%A7')
type(data)読み込んだデータの型も合わせて見ています。
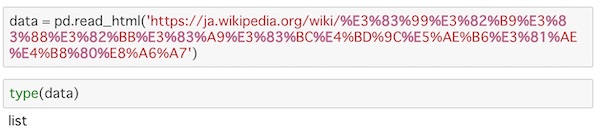
読み込んだデータはリスト型で返されます。
リストデータは次のようにして表示することができます。
data[0].head()head()を使って冒頭の5つだけデータを表示しています。

SQLの読み込み
次はSQLを読み込みます。ただ、SQLのデータベースの扱い自体は個別な知識を得る必要があるので、それについては別で勉強してもらう必要があります。
ここではデフォルトでPythonの標準ライブラリに含まれているSQLiteで簡単にやってみます。
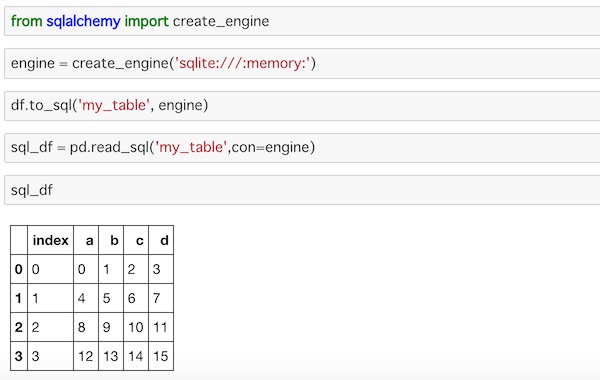
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:')
df.to_sql('my_table', engine)sqlalchemyをインポートします。create_engine()でデータベースに接続しますが、ここではメモリー上のsqliteを指定しています。ちょっと見慣れない書き方ですが、とりあえずはそういうものとしてここでは捉えて起きましょう。(データベース関連は別でしっかり勉強する必要があります)
to_sql()を使ってこれまで使っていたdfをメモリー上に配置したmy_tableに書き込んでいます。
書き込んだデータを読み込むにはread_sql()を使います。
sql_df = pd.read_sql('my_table',con=engine)conでデータベースに接続して、my_tableを指定して読み込んでいます。
この一連のコードを実行するとこうなります。
データベースに関しては、データベース自体の知識を増やした方がいいですね。
最後に
ここでは、Pythonの拡張モジュールPandasを使ってデータの入力と出力を扱いました。
pd.read_メソッドを使ってさまざまな種類のファイルを読み出すことができます。
CSV、Excel、HTML、SQLの4つの一般的なデータ型を扱いました。
どれも同じような要領で行うことができますが、Excelファイルなどはマクロ関数や画像などは扱えず、SQLなどは別にデータベースの知識も必要になるので注意が必要です。

