
データ解析をするためのたくさんの機能を持ったPythonライブラリのPandasについて、データ型のSeries(シリーズ)は見てきました。

引き続き、今度はDataFrameについて扱って行きます。
DataFrameは、一連のデータオブジェクトをまとめて、同じインデックスを共有することができますPandasの主要な機能と言っていいでしょう。
ではPandasのDataFrameを作って行きましょう。
PandasでDataFrameを作る
PythonのライブラリーPandasのDataFrameを扱っていきましょう。
まず、Seriesの時と同様に、NumPyとPandasのライブラリをインポートします。
import numpy as np
import pandas as pdここでは、適当なデータをランダムに作るために、正規分布にしたがった乱数を発生させるrandnをインポートしておきます。
from numpy.random import randn
np.random.seed(100)データを固定する為にseed()も設定しておきます。
さっそくDataFrameオブジェクトを作ってみます。
DataFrame()にデータとインデックス、カラムの値をそれぞれ与えます。
df = pd.DataFrame(randn(5,4),index='a b c d e'.split(),columns='w x y z'.split())
# df = pd.DataFrame(randn(5,4),['a', 'b', 'c', 'd', 'e'], ['w', 'x', 'y', 'z'])ここではデータにrandn()を使って5行4列のランダムな値を生成して与えています。indexとcolumnsに値を与えてsplit()で割り当て、DataFrameを作ります。コメントアウトした下側のようにインデックスとカラムの値をリストで与えても同じ操作になります。
実行するとこうなります。
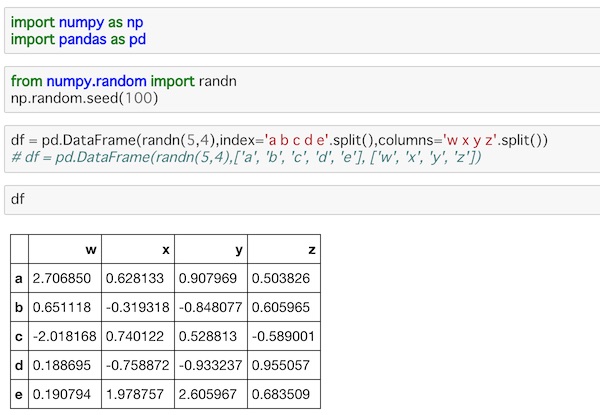
インデックスとカラムが割り当てられた5行4列のデータが表示されました。
このDataFrameからデータを取得するさまざまな方法を扱っていきます。
値の選択とデータの位置(カラム)
先ほど作ったDataFrameからデータを取り出していきましょう。
PandasのDataFrameは、カラムを指定することで、列(縦軸)のデータを取得することができます。
df['w']カラムの’w’を指定してデータを取得します。
実行するとこうなります。
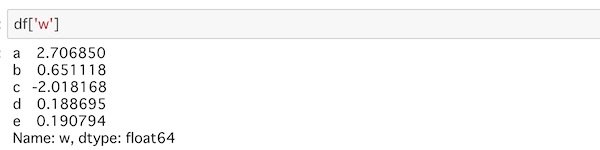
wの列のデータがインデックスラベルと共に表示されています。
ちなみにデータ型を調べてみましょう。
type(df['w'])
type(df)type()を使ってそれぞれ見てみます。
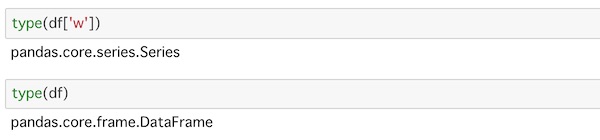
カラムを指定して取り出したもののデータ型はSeriesであるのがわかります。
ちなみにデータはドット(.)でアクセスしても取得できます。
df.wこのとおりです。
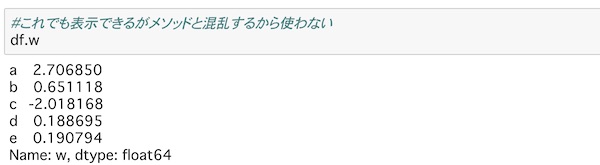
ただし、メソッドも同じ方法で操作するため混乱することにもなるのでこの方法は使わない方がいいでしょう。
データは複数のカラムを指定しても取得できます。
df[['w', 'z']]カラムのリストを与えて取得します。
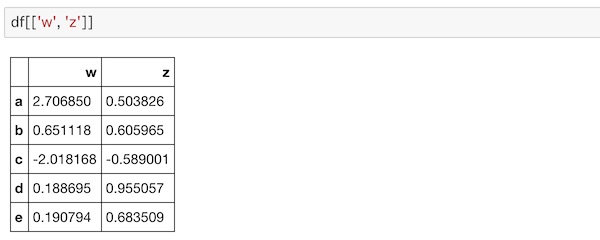
2つのカラムのデータが取得できています。
カラムを新たに追加
カラムは追加することができます。
新しいカラムを指定して、それにデータを代入することで追加できます。
ここでは’new’というカラムを作ります。
df['new'] = df['w'] + df['y']データには’w’と’y’を足したものを代入しています。

右端にカラムが追加されました。
カラムの削除
カラムが追加できたので、今度はカラムの削除をやってみましょう。
カラムの削除にはdrop()に削除するカラムをしてします。
df.drop('new', axis=1, inplace=True)‘new’のカラムを指定します。縦軸のデータなので axisを1に指定します。inplaceをTrueと指定することでデータも削除することができます。
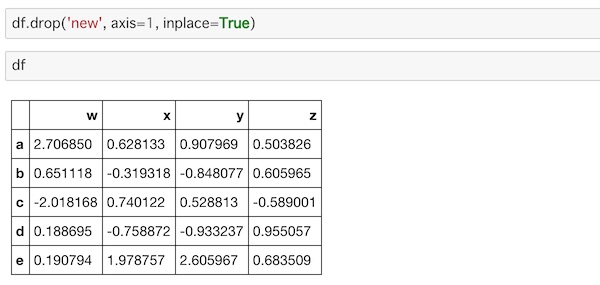
newのデータが削除できました。
行側(row)のデータも同様に削除できます。
引き続き、ラベル’e’の行データを削除して見ましょう。
# df.drop(['e'])
df.drop(['e'], axis=0)axisを0に指定していますが、デフォルトが0なので指定しなくても大丈夫です。
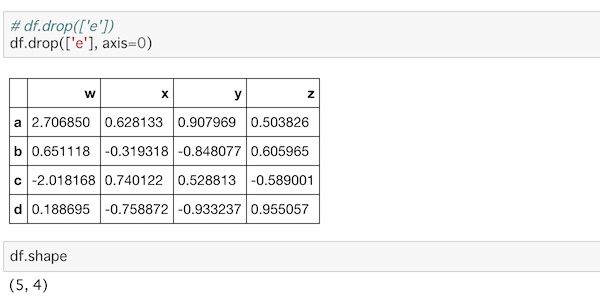
ここでは、先ほどと違ってinplaceにTrueを指定していないので、データ自体は削除されていません。df.shapeで確認すると5行4列のままです。
試しに、’z’、’x’を指定してデータを取り出してみます。
df[['z', 'x']]このように表示されます。
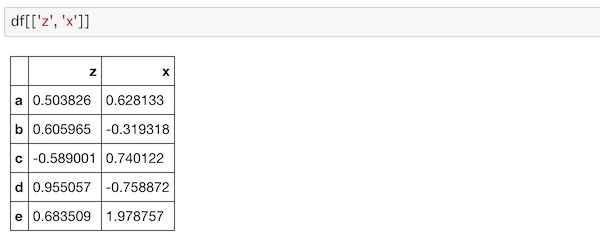
eの行データが残っています。完全に削除するにはinplace=Trueを指定しましょう。
行(row)の選択(loc, iloc)
今度はrow側からみたデータを扱って行きましょう。
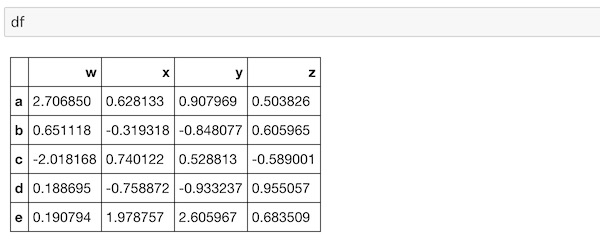
DataFrameを再度確認しておきます。
df実行するとこうなります。
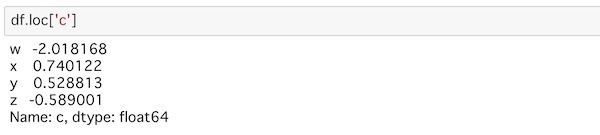
このデータからラベルcの部分の行データを取り出してみます。
locを使ってrowを指定することで取り出すことができます。
df.loc['c']rowのラベルである’c’を指定しています。
指定した行データがカラムのラベルを縦にして表示されています。
このラベル’c’のインデックスは0から数えて2になりますが、このインデックスを指定することでも行データを取り出すことができます。
この時は、ilocを使います。
df.iloc[2]ilocにインデックスを指定しています。
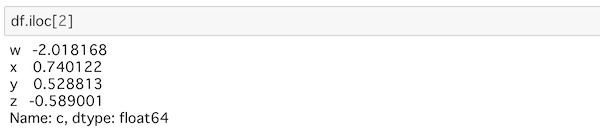
‘c’で指定した時と同じになっています。
rowとcolumnを組み合わせ(サブセット)でもlocを使ってデータを取り出すことができます。
df.loc['b', 'y']
df.loc[['a', 'b'], ['w', 'y']]locに行ラベルと列ラベルをそれぞれ与えています。複数データであれば、それぞれのラベルをリストで渡します。
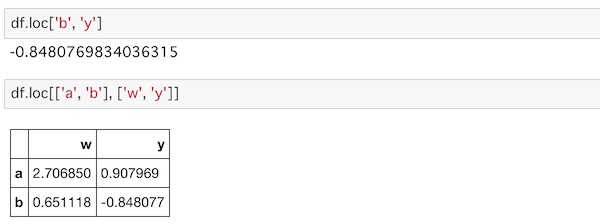
ラベルに対応したデータが取得できています。
条件を指定して選択
PandasもNumPyと同じようにブラケットに条件を指定してデータを選択することができます。
DataFrameを再度確認しておきます。
df次のようになります。

これに条件を指定して取り出してみましょう。
0より大きいという条件を次のように指定してみます。
df > 0
df[df > 0]DataFrameに条件を与えたものと、それをDataFrameで取り出すコードになっています。
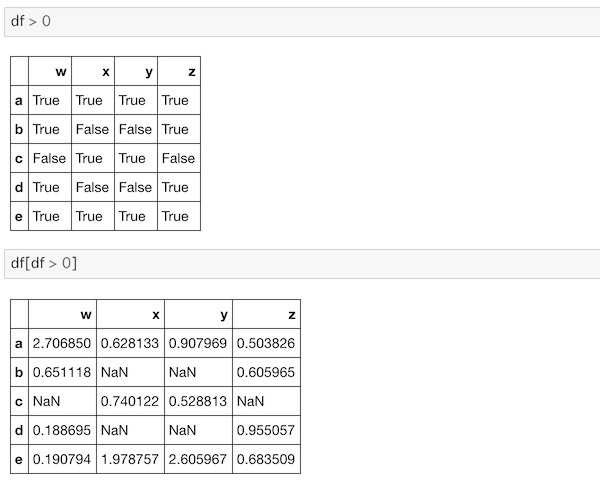
上側はTrue/Falseで出力され、それを元に下側はデータが取り出されているのがわかります。Falseの部分のデータはNaNとなっています。
カラムを指定して条件を与えてみます。
df['w'] > 0
df['w']条件を与えないものと比較して表示してみます。

指定したカラムの部分がTrue/falseで表示されています。
この条件を当てはめたDataFrameを作るとこうなります。
df[df['w'] > 0]
df[df['z'] < 0]条件を変えたものも合わせてやっています。
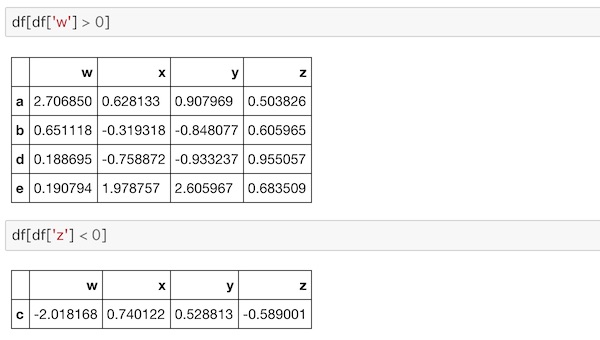
指定したラベルの列データだけでなく、条件にあったラベルの部分の行データを全て取り出す形になっているのがわかります。
これにさらにcolumnのラベルを指定することでデータを絞りこむことができます。
df[df['w'] > 0]['x']
df[df['w']>0][['y','x']]複数のラベルも指定できます。
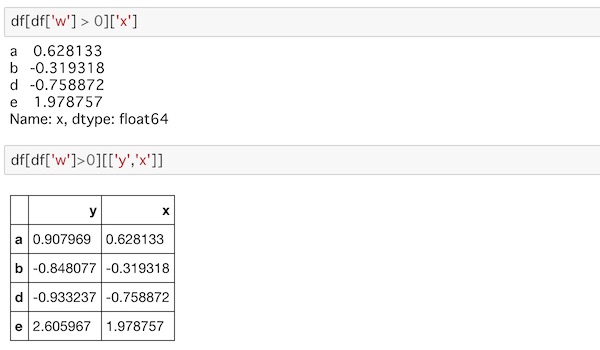
条件にあったデータの中から、指定したラベルで絞り込まれているのがわかります。
複数の条件を組み合わせるにはand, or, notをPythonでは使いますが、PandasのDataFrameで条件指定するとエラーになります。
Pandasでは &, |, ~ を使います。条件部分をそれぞれ丸括弧でくくる必要があります。
df[(df['w']>0) & (df['y'] > 1)]
df[(df['w']>0) | (df['y'] > 1)]andとorについてPandasでやってみました。

その他インデックス設定
その他のインデックスの機能を見てみましょう。
DataFrameを再度表示します。
df実行するとこうなります。
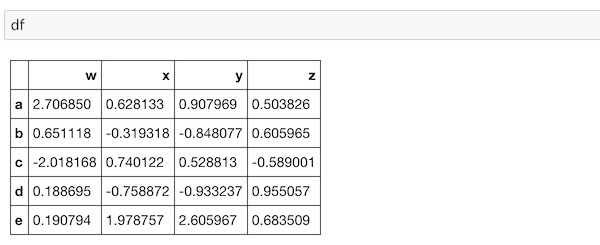
このDataFrameにインデックスを振り直してみましょう。
インデックスを振るには reset_index()を使います。
df.reset_index()こうなります。
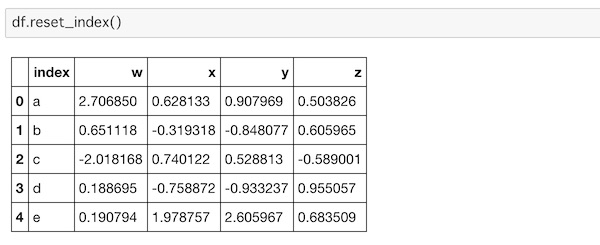
インデックスが0から振りなおされているのがわかります。
ここで新しく次のようにインデックス用のデータを作ろうと思います。
new_idx = 'Mon Tue Wed Thu Fri'.split()次のようになります。

インデックス用のリストが出来上がりました。
これをDataFrameに’Week’のラベルを指定して代入します。
df['Week'] = new_idx次のようになります。
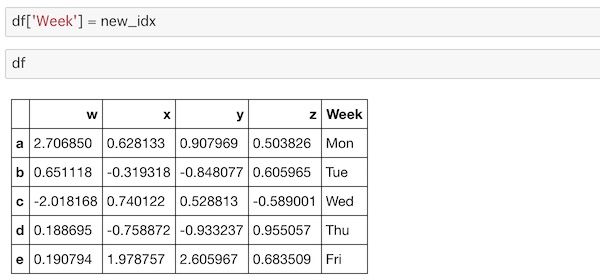
DataFrameの右端に’Week’ラベルが追加され、値が組み込まれています。
このラベルのインデックスにするにはset_index()を使います。
df.set_index('Week')実行すると次のようになります。
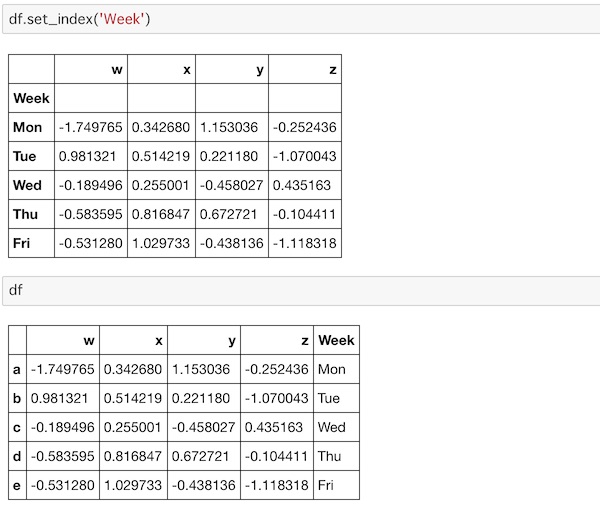
続けて再度DataFrameを表示していますが、インデックスに指定したものが元に戻っています。
これはカラムの削除のところでやったinplaceの設定と同じことです。
次のようにinplaceをTrueに指定することで中身を入れ替えることができます。
df.set_index('Week',inplace=True)実行するとこうなります。
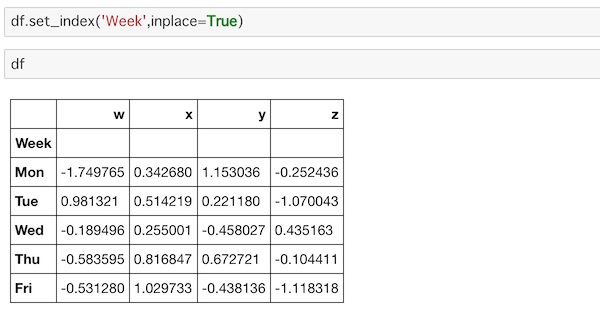
dfで出力しても元に戻っていないのがわかります。
多重インデックスと階層型インデックス
これまではマルチインデックスのDataFrameを作ってみましょう。
次のように複数のインデックスのラベルを用意します。
outside = ['G1','G1','G1','G2','G2','G2']
inside = [1,2,3,1,2,3]
hier_index = list(zip(outside,inside))
hier_index = pd.MultiIndex.from_tuples(hier_index)zip()で2つのリストを1つにまとめていますが、これはタプル形式で組み合わせたリストになっているので、これをMultiIndex.from_tuples()でリスト形式のリストに戻しています。

randn()を使って6行2列のデータを作ります。上のインデックスと、カラムのラベルをa, bで指定して、DataFrameを作ります。
df = pd.DataFrame(np.random.randn(6,2),index=hier_index,columns=['a','b'])次のようになります。

rowのインデックスラベルが2重になっているのがわかりますね。
locにラベルを指定して行データを取り出してみます。
df.loc['G1']
df.loc['G1'].loc[1]外側のラベルのみの指定と、内側のラベルまで指定したデータを取り出します。
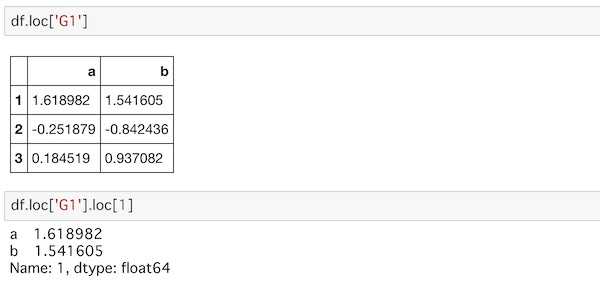
この階層化されたインデックスのそれぞれを表すラベルは今のところはありません。
df.index.names実行するとこうなります。

このインデックスそれぞれにラベルを作って割り当ててみます。
df.index.names = ['Group','Num']‘Group’、’Num’を割り当てています。
DataFrameはこうなります。
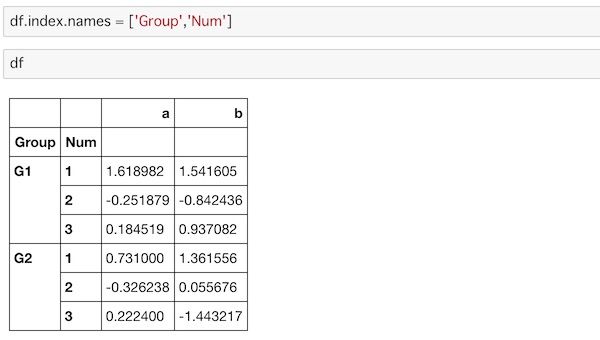
rowのインデックスラベルにそれぞれ名前がついたのがわかります。
xs()を使えばマルチインデックスの特定の階層のデータを取り出すことができます。
df.xs('G1')
df.xs(['G1',1])
df.xs(1,level='Num')先ほど指定したインデックスラベルの名前をlebelで指定することで細かいデータの選択ができます。
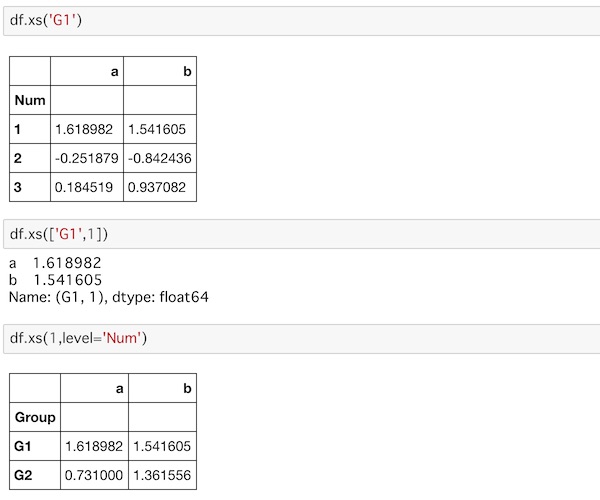
1つ1つ対応関係を確認してみましょう。
最後に
ここではPythonの拡張モジュールのPandasを使って、DataFrameを作る操作を中心に見てきました。
DataFrameは、Pandasの主要な機能と言っていいので、しっかりと操作を理解しましょう。

