
これまで、PythonのNumPyを使って配列を作る方法を学びました。
次はこの配列の個々のデータのインデックスと値の選択、配列をスライスしての選択などをみていきたいと思います。
配列を作る方法に自身がなければ、もう一度復習しておきましょう。

では、配列のインデックスから学んでいきましょう。
配列のindexの操作
jupyter notebookを使って、コードを見ていきたいと思います。
まずはNumPyのインポートと、配列を作ることから始めます。
import numpy as np
arr = np.arange(0, 10)arrという変数に配列を入れています。

このarrを使って、配列のインデックスについて見ていきます。
配列のインデックス
Pythonのリストのでは、リストを代入した変数に角括弧を続けて、その中に取り出したいインデックスを指定すると、値が取り出せました。

これと同様な操作をNumPyの配列(array)でも行うことがでます。
先ほど作ったarrを使ってやっていきましょう。
arr[5]配列もリストと同様に0から始まるインデックスを当てはめることができます。ここではインデックスの5を指定しています。
実行するとこういう結果が得られます。

配列の先頭から6番目の値が出力されているのがわかります。
配列の範囲指定とスライス
配列のスライスも、Pythonリストの時と同じように範囲指定して取り出すことができます。
arr[1:6]
arr[0:6]
arr[:6]
arr[6:]コロン(:)でインデックスを挟んで範囲を指定します。0から始めるか指定せずにコロンで区切ると先頭から、値がとり出されます。コロンの後ろ側は指定したインデックスの前の値となります。

しっかり、インデックスの位置と見比べるとどうスライスされているかわかると思います。
スライスで範囲指定して値を代入すると配列の中身を変更することができます。
arr[0:5] = 10先頭からインデックス5の手前まで(5つ目まで)の値に10を代入しています。

配列の値が変わっているのがわかります。
配列のスライスとコピー
あらためて配列を作り直します。
arr = np.arange(0, 10)
この配列を次のように範囲指定してスライスします。
slice_arr = arr[0:5]
このスライスした配列の値を次のように変更してみます。
slice_arr[:] = 99
ここまでは先ほどやったことと同様なことですね。
これで、もとの配列を見るとこうなっています。
arr
配列をスライスして取り出した部分の値を変えると、元の配列の部分も値が変わってしまっているのがわかります。
配列のスライスは、別の配列が作られる訳ではなく、元の配列の位置をそのまま参照しているということになります。
copy() – 元の配列はどうなる?
先ほどの例でいうと、配列がコピーされている訳ではないということになります。そこで配列をコピーしてみましょう。配列のコピーはcopy()を使って作ることができます。
先ほどのarrをコピーしてみましょう。
arr_copy = arr.copy()コピーした配列をarr_copyとしています。arrと並べて表示してみます。

どちらも同じ値の配列になっています。
では、このarr_copyを、次のように値を変えてみます。
arr_copy[:] = 100全ての値を100に変更した配列になります。
このとき、コピー元のarrはどうなっているでしょうか?
合わせて出力してみます。

arrは元のままです。単にスライスして値を変えただけでは元の配列の値も変わってしまいますが、copy()を使うと別の配列として操作することができるのこれでがわかります。
2次元の配列の操作
これまでの操作は1次元の配列の操作でした。
では2次元の配列を作ってみましょう。
3行3列の配列は次のように作ることができました。
arr_2dim = np.array([[10, 20, 30], [15, 25, 35], [40, 50, 60]])arr_2dimという変数に配列を入れています。

インデックスを指定して取り出すことができます。
これは行データを取り出しています。
arr_2dim[0]1行目の配列が取り出されます。

個々の値も次のようにして行のインデックスを指定し、列のインデックスを指定すれば取り出すことができます。
arr_2dim[0][0]
arr_2dim[1][1]
arr_2dim[2][1]最初が行のインデックス、次が列のインデックス。この位置のデータが出力されます。

これは次のように書くことでも同じ操作ができます。
arr_2dim[2, 1]

値だけでなく、配列も同様です。
arr_2dim[:2, 1:]
こちらのやり方の方が、内部的な処理が早いと言われています。
配列と比較演算子
配列は、比較演算子を使って比較の判定を行うことができます。
再度、配列を作り直してみます。
arr = np.arange(0, 10)
この配列の中で5より大きい値を判断するには、次のようにして行うことができます。
bool_arr = arr > 5これはTrue/Falseで結果が出力されます。
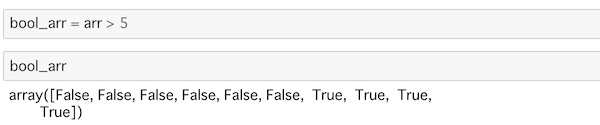
5以下のインデックスの位置がFalse、越えている部分はTrueと表示されているのがわかります。
これは、次のように比較してTrueの値の部分を取り出すことができます。
arr[bool_arr]
arr[arr > 5]
arr[arr <3]
最初のようにbool値を判定した変数を使ってもいいですし、そのまま比較演算子を使ってもいいです。
配列の形状変換とインデックス操作
2次元の配列の操作は行いましたが、おさらい的に配列の形状変換とインデックス操作をまとめてみます。
arange()を使って整数を与え、これをreshape()で2次元の配列を作ります。
0から49の整数を使って、5行10列の配列を作ります。
arr_2dim = np.arange(50).reshape(5, 10)データの数が揃うように値を与えなければいけません。
次のように配列が作られます。

スライスを使って、これまでと同様に取り出すことができます。
arr_2dim[1:4]
arr_2dim[1:4, 3:6]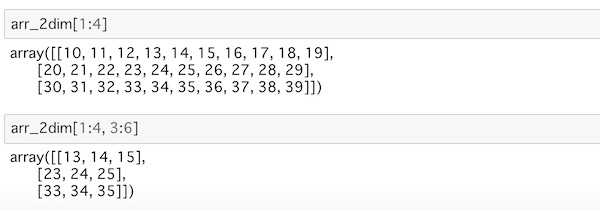
行の位置、列の位置を付き合わせて、どうスライスされているのか確認してみましょう。
最後に
ここではPythonの拡張モジュールのNumPyを使って配列のインデックス操作を見てきました。
Pythonリストの操作と同様な操作でインデックスを指定して、配列の値を取り出したり、スライスすることができます。
copy()と元の配列との関係の違いもしっかり理解して起きたいところです。

