
これまでPythonの拡張モジュールPandasのいろいろな操作をテーマ別に見てきました。
ですが、Pandasの操作にはそういった項目ではまとめられないほどたくさんの操作方法があります。
ここではPandasのDataFrameについて、いろいろな操作方法について見ていきましょう。まず、操作のための任意のDataFrameを作っておきまます。
import numpy as np
import pandas as pd
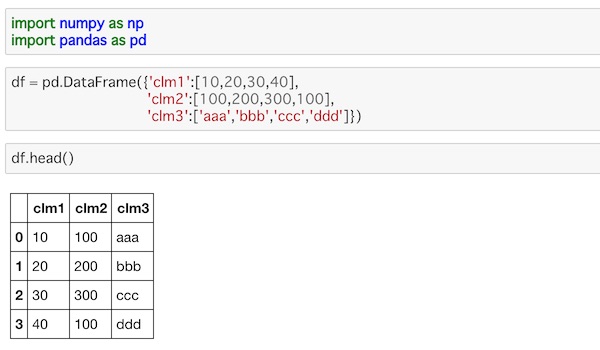
df = pd.DataFrame({'clm1':[10,20,30,40],
'clm2':[100,200,300,100],
'clm3':['aaa','bbb','ccc','ddd']})
df.head()ライブラリーをインポートして3つのカラムとそれぞれ4つのデータを持ったDataFrameを作っています。
表示するとこうなります。
これを使って、DataFrameの操作について様々な方法があるので順に見ていきます。
ユニークな値を調べる
このデータを使って、ここではユニークなデータを扱う操作をしてみます。
‘clm2’を指定して、次のように操作してみます。
df['clm2'].unique()
df['clm2'].nunique() # len(df['clm2'].unique())
df['clm2'].value_counts()unique()は含まれているデータを重複を除いて表示します。nunique()はその数、value_counts()はデータの値とそのデータが存在する数を示しています。
実行するとこうなります。

nunique()はコメントアウトしている部分のようにunique()をlen()を使ってカウントすることと同じです。
データの条件を指定する
DataFrameの中から、条件を指定して値を取り出すことができます。
ここでは’clm1’の中から20より大きいことを指定してみます。
df[df['clm1'] > 20]
df['clm1'] > 20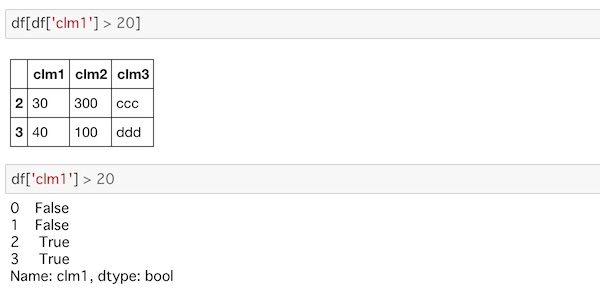
次のように&などを使って条件を組み合わせることもできます。
df[(df['clm1']>20) & (df['clm2']==300)]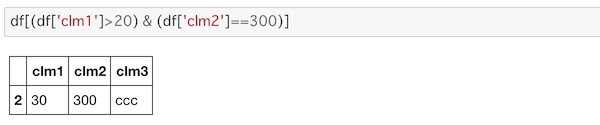
条件にあった部分だけが取り出されているのがわかります。
関数を適用する
DataFrameに関数を適用して操作します。
まずは自作した関数を適用してみます。
次のような関数を作ってみます。
def times2(x):
return x*2これは値を2倍する関数です。
これをDataFrameに適用するには次のようにapply()を使います。
df['clm1'].apply(times2)この関数はlambda関数を使って次のようにも書くことができます。
df['clm2'].apply(lambda x : x*2)それぞれカラムを指定して実行するとこうなります。
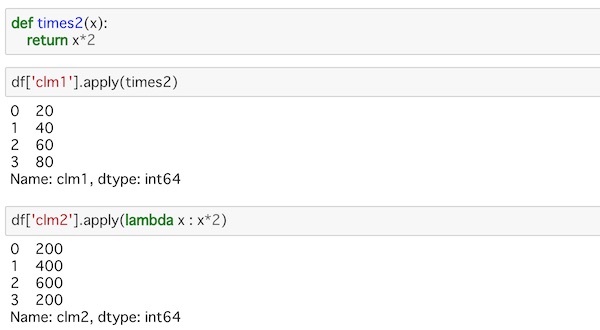
もちろんPythonの組み込み関数も適用できます。
len()を使ってカラム内のデータの長さを調べるには次のようになります。
df['clm3'].apply(len)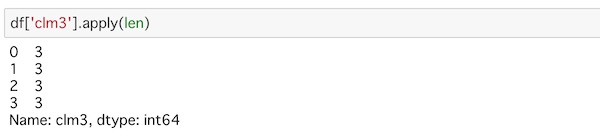
カラムを指定して、そのデータの合計を求めるには次のようにsum()が使えます。
df['clm1'].sum()
特定のカラムを削除する
カラムを指定して、DataFrameからその列データを削除することができます。
それにはdrop()を使ってカラムを指定し、axis=1を適用します。
df.drop('clm1', axis=1)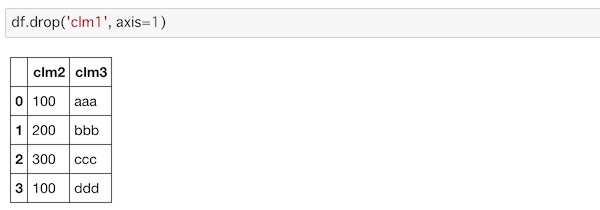
指定した’clm1’のデータが削除されています。
ただし、これは元のDataFrameが変更されている訳ではありません。
完全にDataFrameから削除するには次のようにdelキーワードを使います。
# カラムを完全に削除する
del df['clm1']カラム名とインデックス名を取得
カラム名とインデックス名を取得するには、それぞれcolumnsとindexをドットでDataFrameにアクセスして取得します。
df.columns
df.index
ソートする
DataFrameのカラムを指定して、そのデータをソートすることができます。
ソートするにはsort_values()を使ってカラムを指定します。
df.sort_values(by='clm2')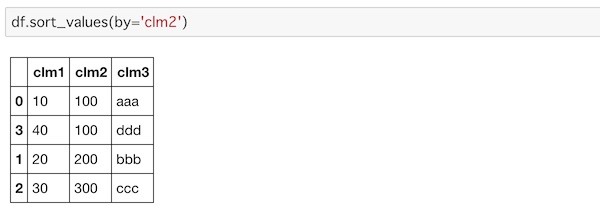
データがソートされているのがわかります。「by=カラム名」で指定していますが、by=を使わずにカラム名だけでもソートできます。
欠損値の扱い
DataFrame欠損値が存在するかどうかはisnullを使います。
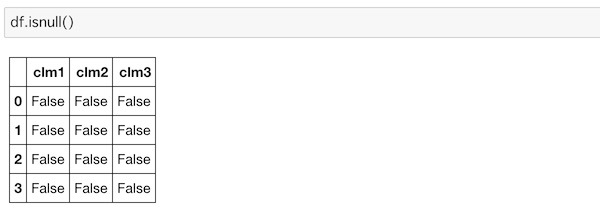
これまで使ってきたDataFrameには全て値が入っているので、Falseのみが返されています。
あらためて欠損値の入ったDataFrameを作って操作していきましょう。
df = pd.DataFrame({'clm1':[10,20,30,np.nan],
'clm2':[np.nan,200,300,100],
'clm3':['aaa','bbb','ccc','ddd']})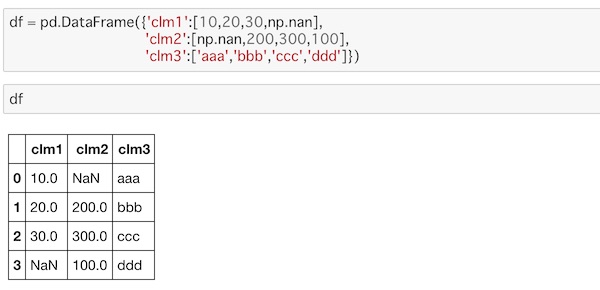
あらためて欠損値の有無を調べてみます。
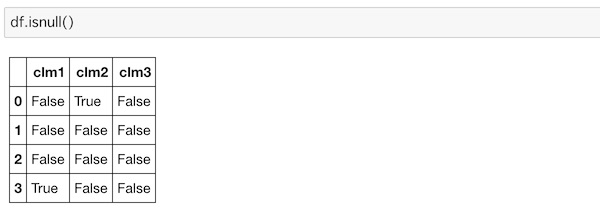
欠損値に該当する部分がTrueで返されているがわかります。
欠損値を削除して取り出すには、dropna()を、欠損値に指定の値を入れて取り出すにはfillna()を使います。
df.dropna()
df.fillna('any')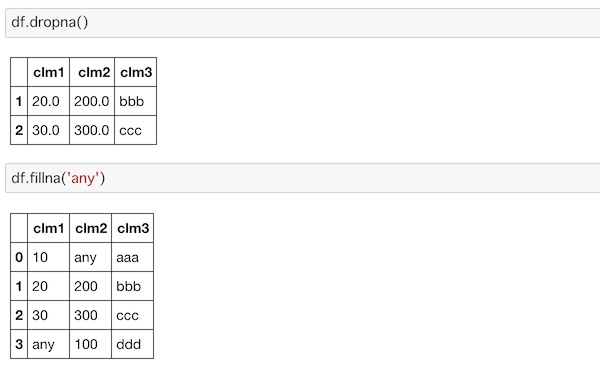
それぞれNaNの行データが削除され、NaNの部分にanyが与えられているのがわかります。
ピボットテーブルを作る
エクセルで表計算するときなどのように、多次元の集計をするピボットテーブルをDataFrameから作ることもできます。
次のようなDataFrameを用意してみます。
dict_data = {'A':['foo','foo','foo','bar','bar','bar'],
'B':['one','one','two','two','one','one'],
'C':['x','y','x','y','x','y'],
'D':[1,3,2,5,4,1]}
df = pd.DataFrame(dict_data)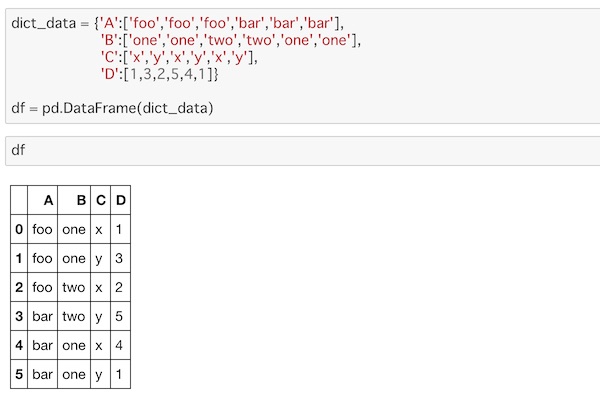
このDataFrameをピポットテーブルにするには、pivot_table()を使います。
Dをデータの値に取り、A、Bをindex、Cをcolumnに割り当てて作ってみます。
次のように書くことができます。
df.pivot_table(values='D',index=['A', 'B'],columns=['C'])
値の無い部分にNaNが入って、きちんと分類されているのがわかります。
最後に
ここでは、Pythonの拡張モジュールPandasのDataFrameの様々な操作方法を見てきました。
DataFramesの操作はこれまでカテゴリー別にまとめて扱ってきましたが、それに収めて説明できない機能もたくさんあるのでここでまとめて扱ってみました。
これまで扱った操作方法同様にしっかり身につけましょう。

