
NumPyに続いて、ここからはPandasについて学んで行きます。
Pandasは、NumPyの上に構築されたパッケージで、データ解析をするためのたくさんの機能を持ったPythonのライブラリです。特に、数表や時系列データを操作するためのデータ構造の分析と演算をすることができます。
ここでは、まずPandasの主要なデータ型であるSeries(シリーズ)を見ていきます。SeriesはNumPyの配列によく似ていますが、NumPy配列とSeriesとの違いは、Seriesは軸ラベルを持つことができるということです。これは、数字で位置を示すものではなく、ラベルでインデックスを付けることができるというものです。
Pandasを利用するにはライブラリをインストールする必要があります。
まだインストールしていないのであれば、ターミナルから次のどちらかのコマンドでインストールしておきましょう。
# Anacondaを利用
$ conda install pandas
# 或いは
$ pip install pandasでは、PandasのSeriesからやっていきましょう。
PandasでSeriesを作る
PythonのライブラリーPandasのSeriesを扱っていきましょう。
まず、Pandasのライブラリをインポートします。NumPyも一緒に使うことが多いですから、合わせてインポートします。
import numpy as np
import pandas as pdPandasはpdとして扱っていきます。
PandasのSeriesの操作を見ていく為に、次のようなデータを用意しておきます。
my_labels = ['a','b','c']
my_list = [100,200,300]
arr = np.array(my_list)
d = {'a':100,'b':200,'c':300}文字列を値に持ったlabelsというリスト、数値の入ったmy_listというリスト、これを使った配列arr、辞書型データのdを用意しています。
実行するとこうなります。
これは特に問題ないですよね。これまでやってきた内容でしかありません。各データ型を作って表示しているだけです。
リストを使う
ではさっそくPandasでSeriesを扱ってみましょう。
まずはリストを使ってみます。コードは次のように書きます。
pd.Series(data=my_list)Series()にdataを指定します。ここではリストのmy_listを与えてみます。
実行するとこうなります。
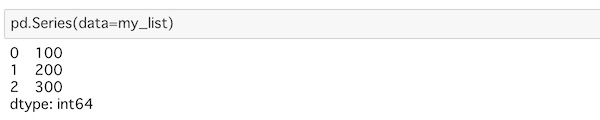
リストのデータが縦方向(列, column)に表示されています。合わせてそれぞれにインデックスが左側に振られているのがわかります。これがPandasの特徴でもありますね。
ラベルを設定する
上の方法に加えて、indexに値を入れてラベルを指定します。
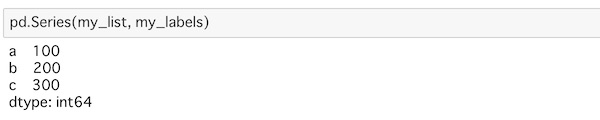
pd.Series(data=my_list, index=my_labels)ここではmy_labelsのリストを入れています。
これは、次のような表示になります。

先ほどとの違いは、インデックスに自分の指定したラベルが当てはめられて表示されていることですね。
pd.Series(my_list, my_labels)dataとindexを用いて代入しなくても、そのまま入力してかまいません。
先ほどと同様に表示されています。
配列を使う
今度は、PandasのSeriesで配列を扱ってみます。
pd.Series(arr)最初で定義したarrを使っています。arrの中身はmy_listと同じです。
実行するとこうなります。
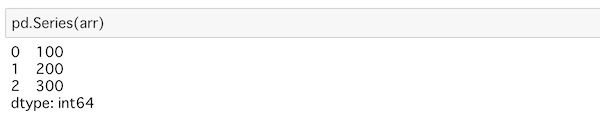
arrの中身がmy_listなので、リストの時と同じ結果になっています。
ラベルを設定する
当然、配列にもラベルをつけることができます。
pd.Series(arr, my_labels)リストの時と同様に、第2引数にラベルを入れています。
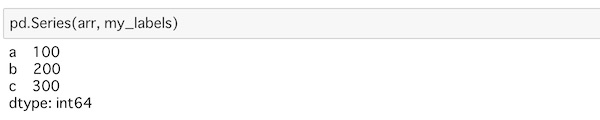
配列とラベルが対応して表示されています。
辞書を使う
次はPandasのSeriesで辞書を扱います。
pd.Series(d)ここでは最初に用意したdを使っています。
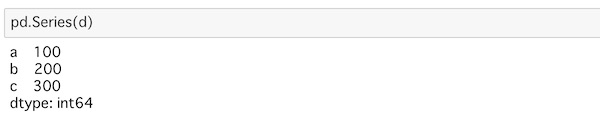
辞書型のデータはキーと値がセットになっていますから、キーがインデックスのラベルとして、値に対応して表示されています。
なんでもSeriesは使える?
PandasのSeriesは、オブジェクトであれば何でも?使えるので、次のような形でも扱うことができます。
pd.Series(data=my_labels)
pd.Series(data=[print, len, max])ラベルで使ったリストであってもdataに使えますし、Pythonの組み込み関数をリストにしても使えます。
これはこのように表示されます。
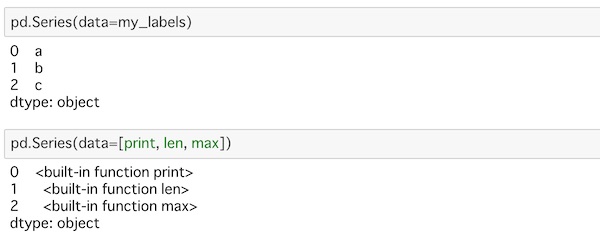
上側は数字のインデックスが振られてラベルの値が表示され、下側は組み込み関数であることが表示されています。
Seriesを操作する
それではPandasで作ったSeriesの簡単な操作をしてみましょう。
まず、2つのSeriesを用意しておきます。
ser_1 = pd.Series([100, 200, 300, 400], ['Python', 'Java', 'PHP', 'Swift'])
ser_2 = pd.Series([100, 200, 500, 400], ['Python', 'Java', 'JavaScript', 'Swift'])値とラベルを指定していますが、3つのラベルと値は同じものにしています。それぞれ1つだけ違うということを確認してください。
表示するとこうなります。
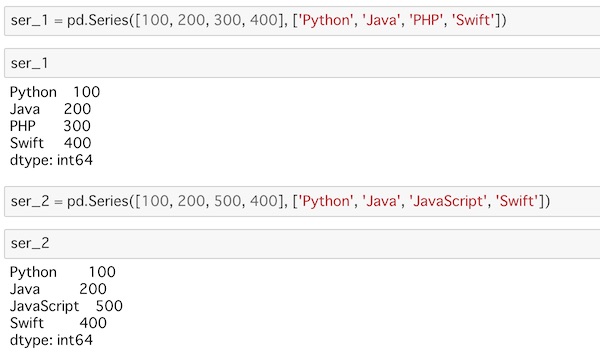
3つ目のラベルと値がそれぞれ違うのがわかると思います。
ラベルを指定して値を取得
Seriesのラベルを指定すれば、対応した値を取得できます。
ser_1のPythonラベルの値を取得してみます。
ser_1['Python']角括弧[]でラベルを指定します。

値が取得できているのがわかります。
インデックスを指定して値を取得
もちろん次のような場合は、インデックスを指定すれば値を取得できます。
ser_3 = pd.Series(data=my_labels)ラベルを値にしたSeriesを作っています。
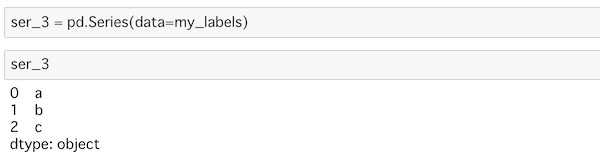
インデックスを角括弧で指定すれば値が取得できます。

インデックスに対応した値が表示されています。
2つのSeriesを加えてみる
次は先ほと用意した2つのSeriesを、次のように足し算してみます。
ser_1 + ser_2どうなるか想像してみるといいのですが、次のような結果になります。
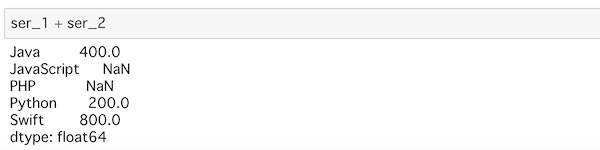
2つのSeriesでどちらにもあるラベルの部分は両方の値が足し算されていますが、片方にしか値のないラベルの部分は、「NaN」となって欠損値となっています。0という値自体も入っていないから足し算されることもなかったというイメージですかね。
最後に
ここではPythonの拡張モジュールのPandasを使ってSeriesを作る操作を中心に見てきました。
応用編でPandasを速習した内容と一部重なっていると思います。

こちらも合わせて見ておくのもいいでしょう。
さらに他のところを含めて、これからじっくりと扱っていきます。

