
Pythonの描画ライブラリseabornのグラフ表示の続きです。ここではグラフのマトリックス表示をやってみようと思います。
マトリックス表示のメソッドを使用すると、データを色分けされた行列としてプロットすることができ、データ内のクラスターを表すために使用することもできます。機械学習などでも利用することになります。
今回もload_dataset()を使ってGitHub上にあるデータセットを使っていきます。
データの準備
ここではseabornのheatmapとclutermapを見ていくことにします。
jupyter notebookにライブラリーをインポートしてデータの準備をしておきます。
import seaborn as sns
%matplotlib inline
tips = sns.load_dataset('tips')
flights = sns.load_dataset('flights')今回は、tipsだけでなくflightsのデータも読み込んで利用します。
それぞれのデータの冒頭5データを表示しておきます。
tips.head()
flights.head()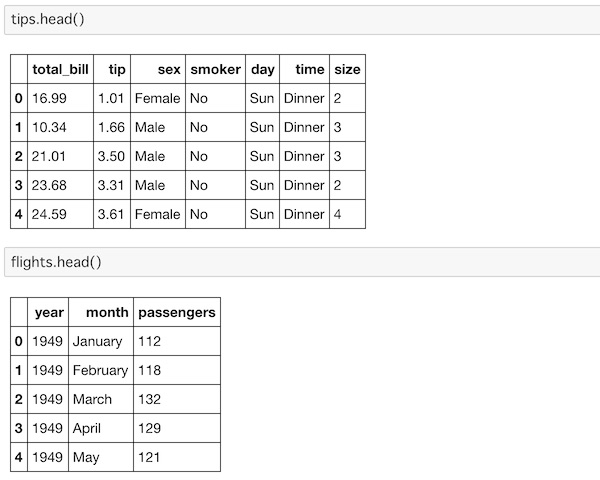
これらを使ってマトリクス表示を扱って行きましょう。
heatmapとclustermap
ここではseabornのheatmapとclustermapを見ていくことにします。
準備したデータを使って順に見ていきましょう。
heatmap()
まず、heatmap()からみて行きます。ヒートマップが正しく機能するためには、データはすでにマトリックス形式でなければなりません。
corr()を使ってtipsデータの相関係数を出してみます。
tips.corr()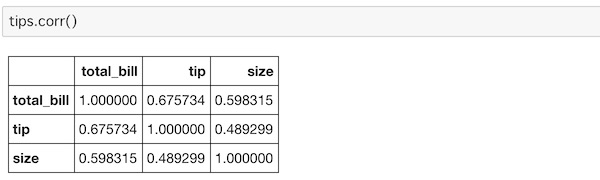
これをheatmap()を使って表示します。
sns.heatmap(tips.corr())heatmap()に相関データを入れています。
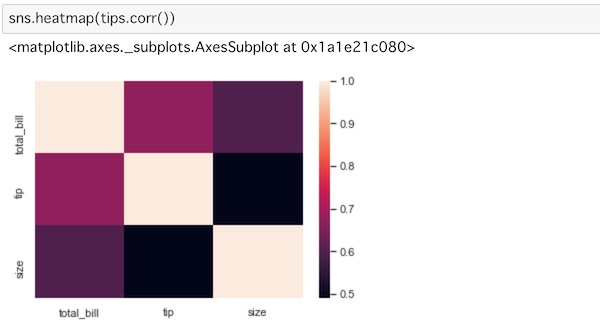
相関データをヒートマップで表すことができました。
このヒートマップを少し加工してみます。
sns.heatmap(tips.corr(),cmap='coolwarm',annot=True)cmapにcoolwarmを指定してカラーリングを変えています。annotをTrueとすることで、ヒートマップのセルに値を出力することができます。
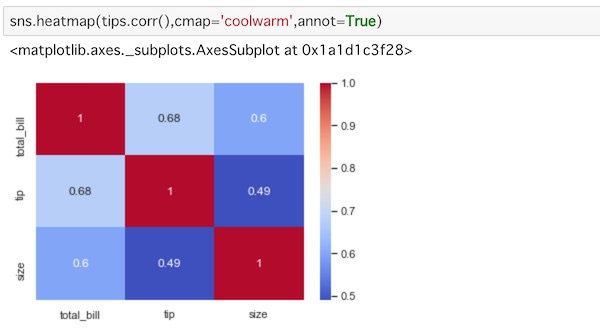
データの大きさに応じたカラーリングとデータ表示がなされているのがわかります。
今度は、flightsデータを使って見て行きましょう。
マトリックス形式のデータと言えば、ピボットテーブルです。flightsデータをピボットテーブルで読み込んでみましょう。
flights.pivot_table(values='passengers',index='month',columns='year')
pivot_table()でglightsデータを読み込んでいます。valuesをpassengersにして、indexをmonth、columnsをyearに設定して表示します。
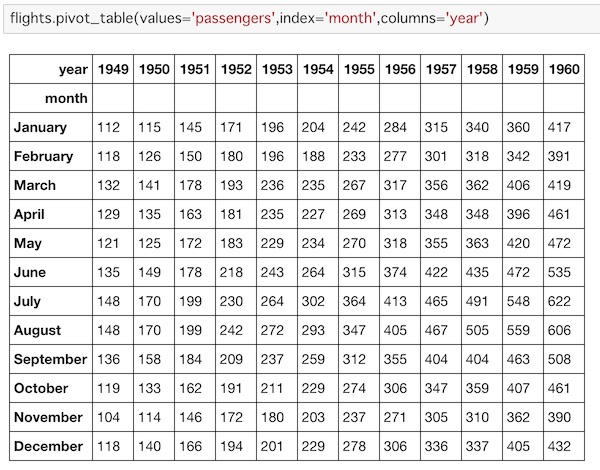
年毎の月別顧客データのマトリクス表示ができました。
このデータをheatmap()に渡して表示してみます。
pvflights = flights.pivot_table(values='passengers',index='month',columns='year')
sns.heatmap(pvflights)
数値を見るよりもイメージが掴みやすくなりました。年々増加していますが、特に7月、8月が多いという感じです。
このグラフをもう少し見栄えを変えてみます。
sns.heatmap(pvflights,cmap='magma',linecolor='white',linewidths=1)cmapでカラーマップをmagmaに変えてみました。linecolorを白に指定してセルの間に線を入れます。その幅はlinewidthsで指定します。
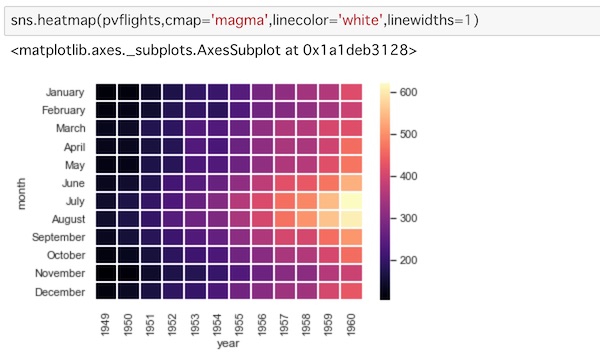
ちなみにcmapのパラメータはmatplotlibのドキュメント内にあります。

clustermap()
clustermap()は、階層的クラスタリングを使って近い属性を持つカテゴリーが近くなるようなヒートマップを表示します。
同じflightsデータを使ってclustermapを表示してみます。
sns.clustermap(pvflights)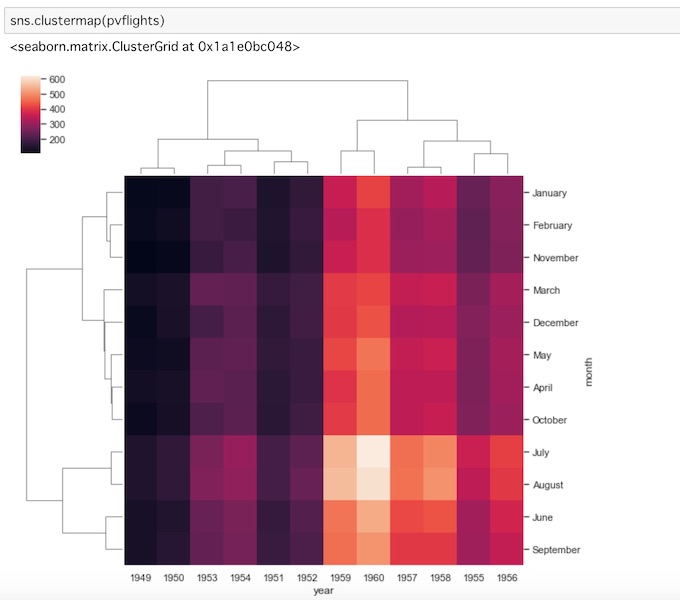
これは、年月が順番どおりではなく、乗客数である値の類似性によってグループ分けされています。ここでは、8月と7月のようなデータから事柄を推測することができることを示していて、両方とも夏の旅行の時期と読み取ることができます。
この情報をもう少し修正を加えてみます。。
standard_scaleを設定して、データの標準化を行ってみます。 標準化とは各列または各行のデータとの最小値の差を取り、それを最大値で割ったものです。0 (行), または 1 (列) で指定します。
sns.clustermap(pvflights,cmap='coolwarm',standard_scale=1)cmapをcoolwarmを指定し、standard_scaleを1に設定してみます。
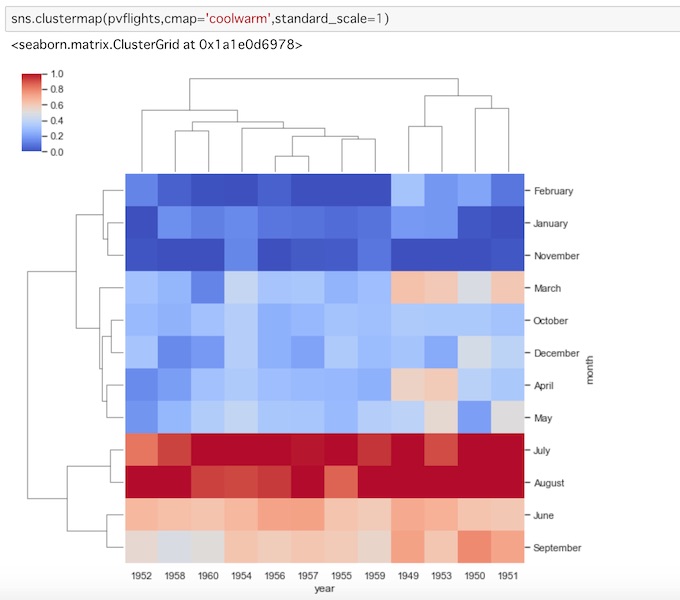
データの分布の違いがより明確になりました。
最後に
Pythonの描画ライブラリseabornのグラフ表示について、ここではマトリックス表示をやってみました。
マトリックス表示によって、データを色分けされた行列としてプロットすることができ、データ内のクラスターを表すことができます。
heatmap()とclustermap()の表示をここでは行いました。マトリクス表示にするには、利用するデータをマトリックス形式にしておく必要があります。

