
PandasはPythonでデータ解析を行うための機能を持ったライブラリで、数表や時系列データを操作するためのデータ構造を作ったり演算を行うことができます。
ここではPandasの基本的な使い方を一気に学んでいきます。
Anacondaを使っているなら、Pandasはすでにインストールされているのではないかと思いますが、入っていなければターミナルからcondaコマンドやpipコマンドでインストールしましょう。
NumPy同様に、ここでもjupyter notebookを利用します。
Pandasの基本的な使い方を一気に学ぶ
jupyter notebookを起動したら、まずはPandasをインポートしましょう。
import numpy as np
import pandas as pdNumPyを利用しての計算も後々出てくるので、合わせてインポートします。Pandasは慣例としてpdとして利用します。
Series()で1次元のデータを作る
まずPandasで1次元のデータを作ってみます。これにはSeries()を使います。
リストに入ったデータを利用して次のように書きます。
import numpy as np
import pandas as pd
s = pd.Series([1, 2, np.nan, 4])
s(以降はインポート文は省略して説明しています)
4つのデータが入っているのがわかりますね。
[shift]+[return]キーで実行して、sを表示します。
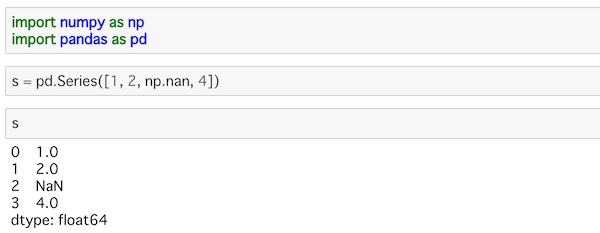
インデックスと対応させてデータが表示されているのがわかります。
インデックスを指定して値を表示したり、メソッドを利用して合計を求めたりすることができます。
s[1]
s.sum()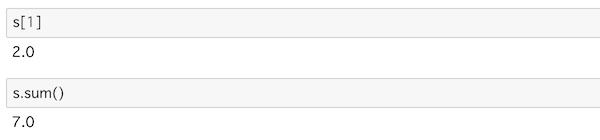
このあたりはNumPyと同じような操作ですから他のメソッドも利用できますね。ちなみにドット(.)を入力した時に[tab]キーを押せば、メソッドの一覧が表示されます。
DataFrame()で2次元のデータを作る
次は2次元のデータです。こちらの方が利用する機会が多いでしょう。DataFrame()を使って2次元の値を与えることで作成できます。
次のように辞書型データを使っても作ることができます。
df = pd.DataFrame({'A': [10, 20], 'B': [15, 45]})
df慣例として変数をdfにすることが多いです。
これを実行するとこうなります。

このように縦横のマトリクスに対応したデータが表示されます。
データのタイプは次のようにして確認できます。
df.dtypes
DataFrame()を操作する
DataFrame()を使った2次元のデータの作成はわかりましたが、本来のデータは多く、もっと複雑ですので整理などが必要となります。
そこでDataFrame()の様々な基本操作の方法をここで一気にみていきましょう。
まず6行4列のデータをrandomを使って作ってみます。
df = pd.DataFrame(np.random.randn(6, 4))
df
ここまではいいのですが、データの項目が一体何なのか、これでは意味を理解することができません。
データにラベルをつける
そこで、縦と横の項目にラベルをつけていきます。
df = pd.DataFrame(np.random.randn(6, 4), pd.date_range('20180101', periods=6), columns=['A', 'B','C', 'D'])
dfdate_range()を使って縦の項目にラベルをつけます。ここでは日付を入れました。preriodsにはデータの数を指定します。横の項目にはcolumsにリストでラベルを指定してあげます。
実行するとこうなります。
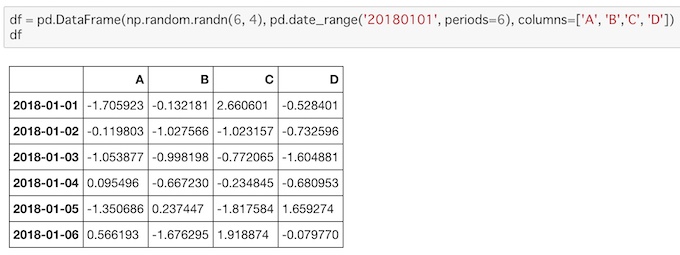
縦、横それぞれの項目が表示されたので、データの意味がわかりやすくなりました。
head()でデータの先頭、tail()でデータの末尾を表示する
データの先頭行を表示するならdead()を使います。
df.head(1)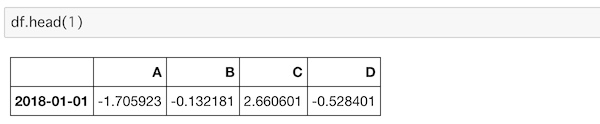
ここでは数字の1を入れて操作しましたが、丸括弧()に数字を入れなければ、先頭から5つのデータが表示されます。
末尾のデータを表示させるならtail()を使います。
df.tail(3)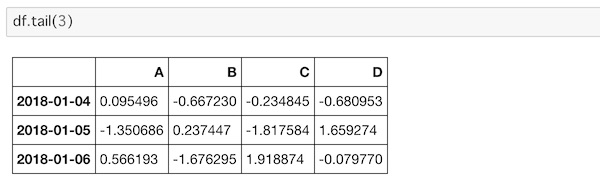
3を入れているので末尾から3つのデータを表示しています。数値を入れなければ5つのデータが表示されます。
index, columns, valuesで縦軸、横軸、中身を表示
データの縦軸の表題(インデックス)、横軸の表題(カラム)、データの値をそれぞれ表示させるには次のコードを使います。
df.index
df.columns
df.values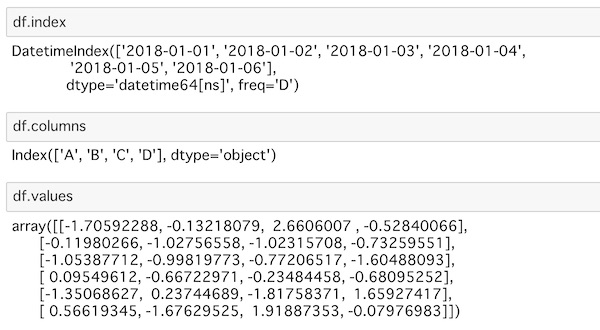
describe()で基本統計量を取得する
describe()を使えば基本統計量を取得できます。
df.describe()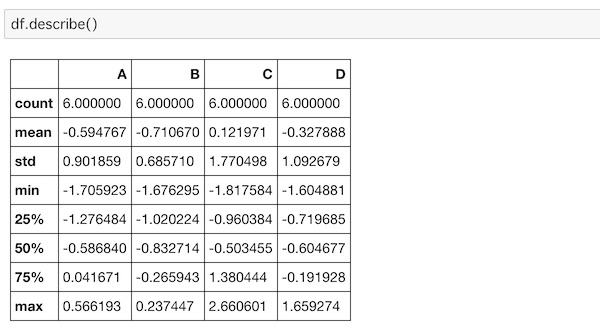
それぞれ、件数 (count)、平均値 (mean)、標準偏差 (std)、最小値(min)、第一四分位数 (25%)、中央値 (50%)、第三四分位数 (75%)、最大値 (max) を確認できます。
行と列の転換、値のソート
行と列の転換にはTを、値のソートにはsort_values()を使います。
df.T
df.sort_values('C')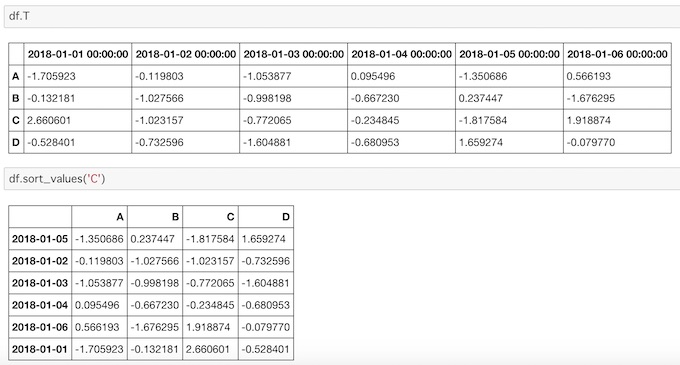
Tで縦横が変換されているのがわかります。ソートはCの項目で小さい順に並び替えられているのがわかります。
データのスライス
リストと同じように、データの縦方向のインデックスやラベルの値を使って範囲指定してデータをスライスすることができます。
df[1:4]
df['20180102':'20180104']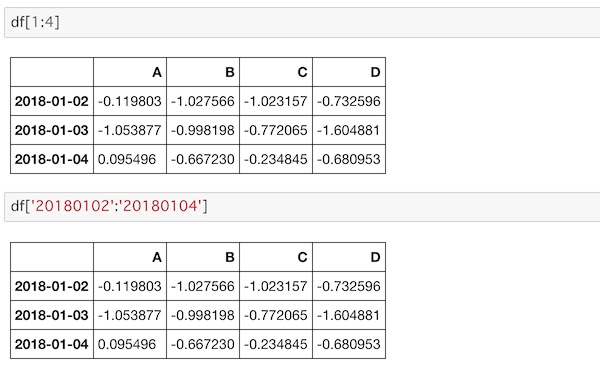
行、列を指定してデータを参照する
行、列を指定してデータを参照するには、loc、ilocを使います。
locは行、列のラベルを使います。
df.loc['20180101']
df.loc['20180103', ['A', 'B']]
df.loc['20180102':'20180104', ['A', 'B']]
df.loc[:, ['A', 'B']]
ilocは行、列の番号を使います。
df.iloc[0, 0]
df.iloc[0:2, 0:2]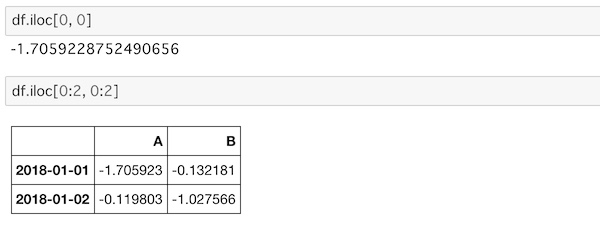
不等号で取り出す
ある条件のデータでゼロより大きい値を取り出してみます。
まずラベルAのデータがゼロより大きい時のデータ。そしてゼロより大きい全てのデータ。言葉で書くとわかりずらいので、次のような場合です。
df[df.A > 0]
df[df > 0]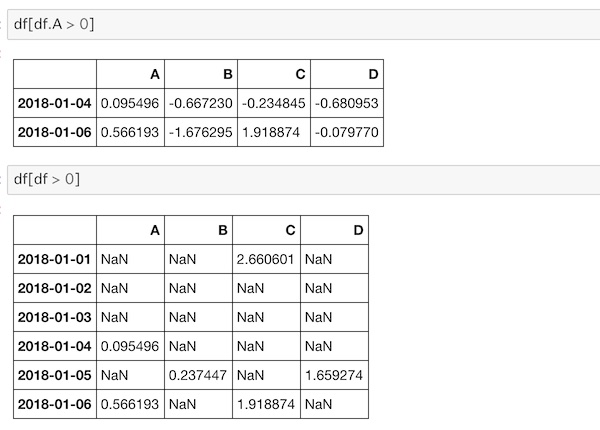
上側がAで該当する列のデータを抽出、下側は0以下のデータはNaNと表示しています。
copy()と列の追加
もう一度、dfの内容を確認しておきます。
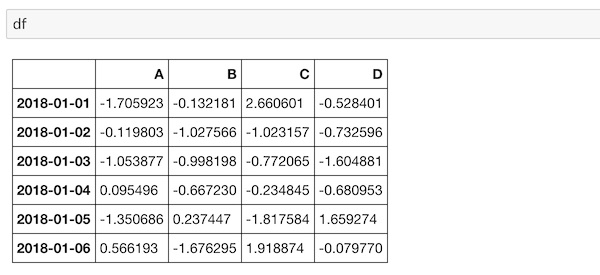
ここで、このデータをコピーして、E列を加えてデータを入れてみたいと思います。
df2 = df.copy()
df2['E'] = ['a', 'a', 'd', 'c', 'd', 'b']
df2copy()で複製することができます。この複製をdf2とします。これにE列をしてして値を入れています。
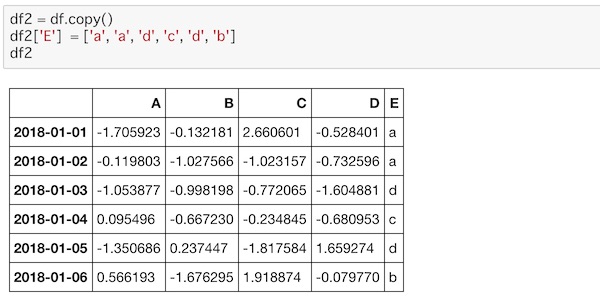
E列に値が入っているのがわかります。
isin()を使って、値が入ってる列のデータを取り出すことができます。
df2[df2['E'].isin(['a', 'c'])]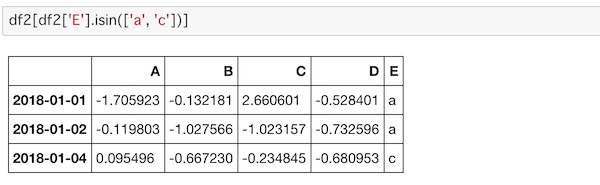
新たな1次元データを列データに加える
ここで1次元のデータを作ってみます。
s = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20180101', periods=6))
s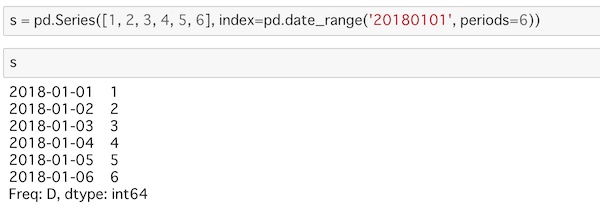
このデータsをdfに項目Eとして付け加えるには次のように書きます。
df['E'] = s
df
shift()でデータをシフトする
shift()を使ってデータをズラすことができます。
df.shift(1)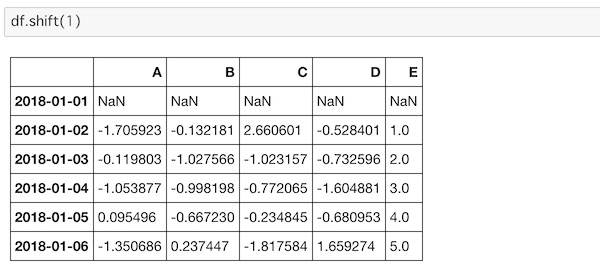
元の1行目から下にずれているのがわかると思います。
concat()で連結する
扱いやすいように新しい小さなデータを作ります。
df = pd.DataFrame(np.random.randn(2, 2))
df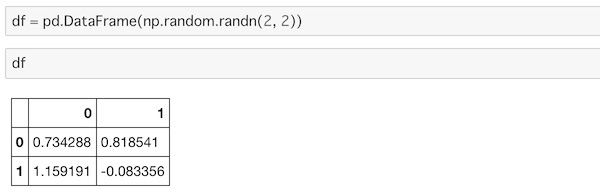
2行2列のデータを作ります。このデータを2つ連結するには、concat()を使います。
pd.concat([df, df])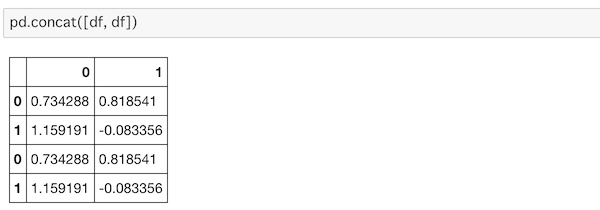
行を増やす形で連結されているのがわかります。
append()で追加する
また新たにデータを作ります。
df = pd.DataFrame(np.random.randn(8, 4), columns=['A', 'B', 'C', 'D'])
df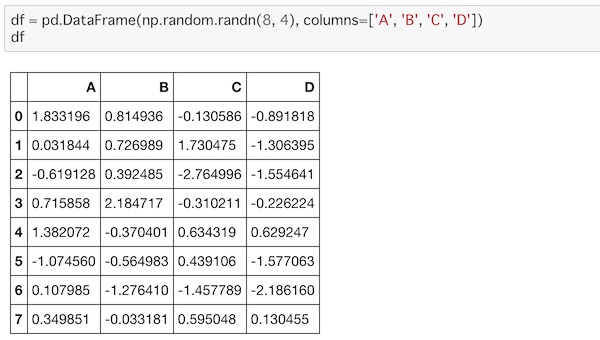
ここにデータの1行目を参照して、新しい一次元データを作ってsに代入します。
s = df.iloc[0]
s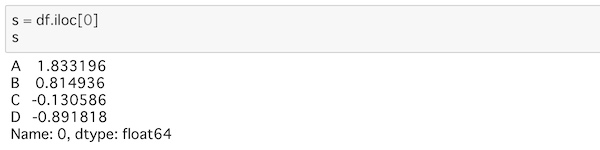
このデータsを、元のdfにappend()で追加します。
df.append(s)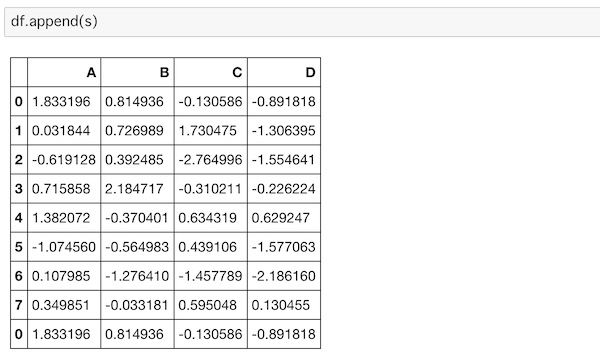
最後の行にsのデータが追加されているのがわかります。
ただ行番号の0が2つあってちょっとデータとして扱うにはおかしくなる場合がありますよね。
そこで次のように、ignore_index=Trueとして書き直すことで、新しく追加されるデータに新しい行番号が割り振られます。
df.append(s, ignore_index=True)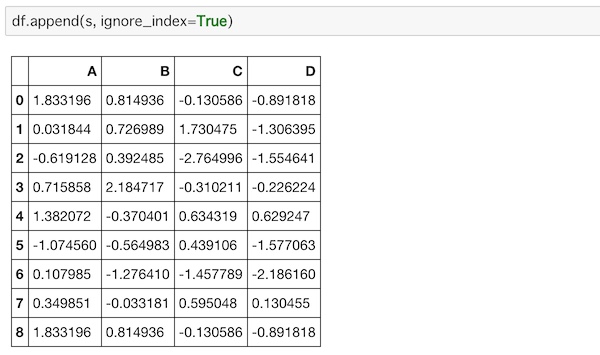
行番号が整えられました。
groupby()で要素をグループ化
再度、作業用に新しいデータを作ります。
df = pd.DataFrame({'A': ['a', 'b', 'a', 'b'], 'B': np.random.randn(4)})
df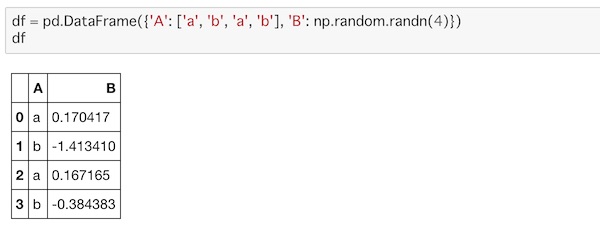
このデータには、A列のデータにa, bがそれぞれ2つ入っています。groupby()を使えば、そ子に含まれる同じ要素をグループ化することができます。
次のコードは要素をまとめてその要素ごとに合計します。
df.groupby('A').sum()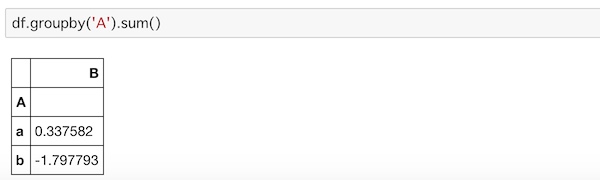
a, bそれぞれの値がまとめられてsum()で合計されているのがわかります。
最後に
Pandasの基本的な操作を簡単ですが一気に見てきました。途中、NumPyを途中で使うことがあるように、どちらもデータの扱いには必要なライブラリです。
もちろんこれ以外にも様々な機能があり、データを外部から読み込むライブラリもあとで扱います。これで終わりではありませんので、さらに詳しいところは別のところでじっくりやろうと思います。

