
データ分析をPythonで行うにあたって、ライブラリのNumPyを使えば数値計算を効率的に行うことができます。
NumPyを利用するにはライブラリをインストールする必要があります。
まだインストールしていないのであれば、ターミナルから次のどちらかのコマンドでインストールしておきましょう。
# Anacondaを利用
$ conda install numpy
# 或いは
$ pip install numpyでは早速NumPyの配列(array)からやっていきましょう。
NumPyで配列を作る
ここではjupyter notebookを使って行きます。jupyter notebookを起動してPythonを使えるようにnotebookを開いて、順にコードを入力して行きます。
まずライブラリーをインポートしておきましょう。
import numpy as npでは、NumPyの配列(Array)を作って行きましょう。
array()
NumPyのArrayはPythonのリストに似ています。リストでは次のように書きます。
my_list = [1, 2, 3]jupyter notebookに入力して実行すると次のように表示されるのはわかりますね。
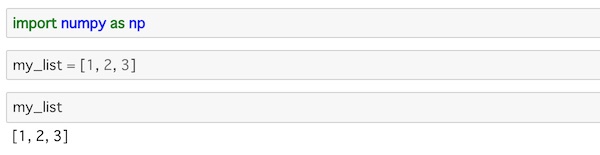
Pythonのリストは、文字列や数字も合わせて値にとりますが、データ分析ではそこは揃える必要があります。
NumPyのarray()にPythonのリストを渡すことで配列を作ることができます。ここでは1次元の配列になります。
arr = np.array(my_list)配列は次のように出力されます。

Pythonのリストのリストはどうでしょう?
my_mat_list = [[1, 2, 3],[4, 5, 6],[7, 8, 9]]こちらもそのまま出力されます。

これをarray()で配列にすると多次元の配列になります。

ここでは3行3列のデータの配列になっています。
arange()
arange()は、開始値、終了値の指定の範囲の数値で、連番の配列を作ることができます。
np.arange(0, 10)0からはじめて10の手前までの数値の配列を作ります。
また、arange()は、開始値、終了値だけでなく、第3引数にデータの間隔を与えることでいくつ毎の数値の配列を作るかを指定することがで来ます。
np.arange(0, 10, 2)これは先ほどと同じ範囲から2づつ増やした数値の配列を作ります。
実行するとそれぞれこうなります。
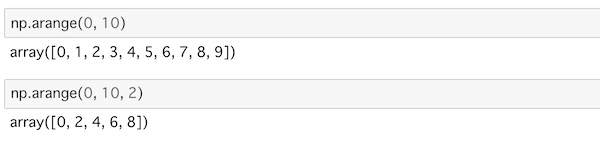
終点に与えた数字自体は含まれないことに注意しましょう。
zeros()
zeros()は値がゼロのみの配列を作ります。引数に与えたデータ数を持つ配列になります。
np.zeros(5)また、zeros()はタプルで数値を与えることで2次元の0の値を持つ配列を作ることができます。
>np.zeros((2, 3))それぞれ次のようになります。

上側は0が5つの配列。下側は2行3列の値が0の配列が出来ています。
ones()
one()はzeros()の値が0から1に変わっただけで、値が1のみの配列を作ります。
これは1が5つの配列を作ります。
np.ones(5)こちらは2行3列で値が全て1の配列を作ります。
np.ones((2, 3))実行するとそれぞれこうなります。

linspace()
linspace()は始点と終点の値を与え、第3引数に要素数を与えることで、始点から終点までの値を要素数だけ等間隔の値で配列を作ります。等差数列ですね。
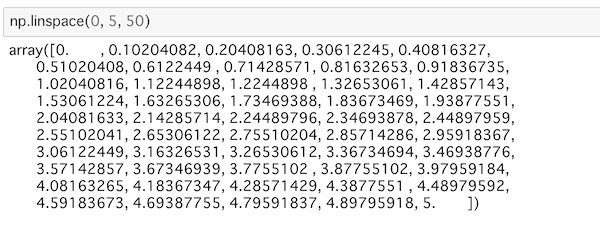
np.linspace(0, 5, 50)これは0から5までの値を等間隔に50個の配列を作ります。
実行するとこうなります。
eye()
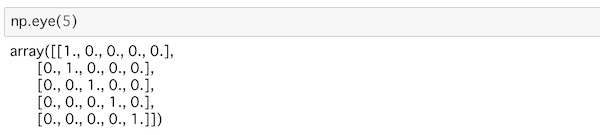
eye()は引数に与えたnに対してn×nの対角線上に値が1が入り他は0の配列を作ります。単位行列というやつですね。
np.eye(5)これは、5行5列の単位行列の配列が作られます。
randomモジュールで乱数の配列を作る
Pythonの標準モジュールと同様にNumPyにはrandomモジュールがあり、簡単に乱数を発生させて、配列を作ることができます。
rand()
rand()は0以上、1未満の範囲で一様乱数を出力します。引数を与えることで、その個数の乱数を発生させます。
np.random.rand(5)一様乱数を5つ発生させて配列を出力します。
np.random.rand(5, 5)こちらは5行5列の一様乱数を発生させて配列を生成します。
それぞれ実行すると次のようになります。
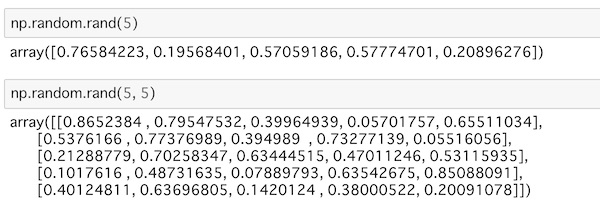
当然ながら、乱数ですから毎回同じ値が生成される訳ではありません。
randn()
randn()は平均0、標準偏差1の正規分布に従う乱数を発生させます。
np.random.randn(5)こちらは5つの乱数を発生させて配列を作ります。
np.random.randn(3, 3)こちらは3行3列の乱数を発生させて配列を生成します。
実行するとそれぞれこうなります。

randint()
randint()は指定の範囲内の整数で乱数を発生させます。
np.random.randint(1, 100)こちらは1から99までの整数の値をランダムに返します。
np.random.randint(1, 100, 10)こちらは1から99までの整数の値を10個ランダムに返します。
それぞれ実行するとこうなります。

配列の形状変換、最大値、最小値、データ型
配列の形状変換、最大値、最初値、データ型などをみていきましょう。
ここでは、次のように変数を作って扱っていきましょう。
arr = np.arange(25)
randarr = np.random.randint(0, 100, 10)これはそれぞれ次のように出力されます。

これを操作していきます。
reshape()
reshape()は1次元の配列を形を指定して2次元の配列に変換します。
arr.reshape(5, 5)これは、先のarrを5行5列の配列に変換します。ただ、データの値の数が変換する形に合わなければ変換はできません。
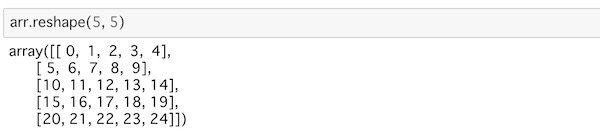
これは次のようにデータを指定し、タプルやリストで変換後の形を指定しても同じです。
np.reshape(arr, (5, 5))
max(), min()
配列の値の最大値、最小値を求めるには、max(), min()を使います。
randarr.max()
randarr.min()先のrandarrの最大値、最小値を求めています。
次のようになります。

argmax(), argmin()
argmax(), argmin()で配列の最大値、最小値のインデックスを知ることができます。
randarr.argmax()
randarr.argmin()実行するとこうなります。
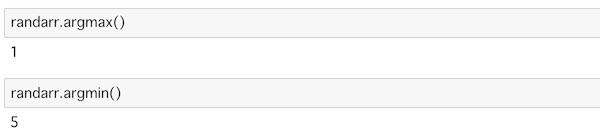
見比べて見ると、インデックスの位置にそれぞれの値があるのがわかるはずです。
shape, dtype
配列の変数にshapeでアクセスするとその配列のサイズがわかります。またdtypeを使うと配列の値のデータ型を得ることができます。
arr = arr.reshape(5, 5)
arr.shape
arr.dtype実行するとこうなります。

5行5列の配列で、データ型がint64であることがわかります。
最後に
ここではPythonの拡張モジュールのNumPyを使って配列を作る操作を中心に見てきました。
応用編でNumPyを速習した内容と重なっている部分も多いです。

こちらも合わせて復習しておくのも良いでしょう。
これ以外のところを含めて、これからじっくりと扱っていきます。

