
Pythonの拡張モジュールPandasのDataFrameの操作をしてきましたが、複数のDataFrameを組み合わせる必要がある場面も出てきます。
PandasにはDataFramesを組み合わせる方法として、主に3つの方法があります。ここでは、merge(), Join(), concate()を使って組み合わせの方法を見て行こうと思います。
concat()
まずはconcat()から見ていきましょう。
concat()を使えば、基本的にDataFrameをつなぎ合わせることができます。ただし、連結するデータの次元が一致する必要があることに注意が必要です。
jupyter notebookでPythonを起動してpandasをインポートしてます。例として次のようなDataFrameを3つ作ってみます。
import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'C': ['C0', 'C1', 'C2']},
index=[0, 1, 2])
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5'],
'C': ['C3', 'C4', 'C5']},
index=[3, 4, 5])
df3 = pd.DataFrame({'A': ['A6', 'A7', 'A8'],
'B': ['B6', 'B7', 'B8'],
'C': ['C6', 'C7', 'C8']},
index=[6, 7, 8])実行してみます。

それぞれのDataFrameを表示すると次のようになります。

pd.concat()にDataFrameのリストを渡して、連結することができます。
次のように先に用意した3つのDataFrameをリストで渡してみます。
pd.concat([df1,df2,df3])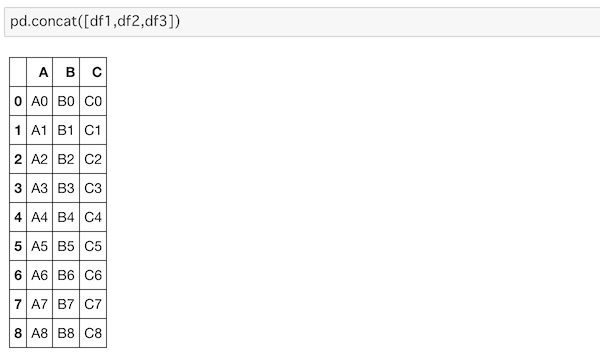
columnが全て揃っているので縦方向に連結されているのがわかります。
同じconcat()にaxis=1を渡すことで、横軸方向に連結することができます。
pd.concat([df1,df2,df3],axis=1)
columnが横に連結される形になっていますが、インデックスが揃った値ではないので該当しない部分にはNaNが入れられて表示されています。
merge()
次はmerge()を扱ってみます。
merge()を使用すると、SQLテーブルをmergeするのと同様のロジックを使用してDataFrameを連結することができます。
次のような共通のキーを持つ単純なDataFrameを2つ用意してみます。
df_left = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']})
df_right = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']})それぞれのDataFrameを次のように表示されます。
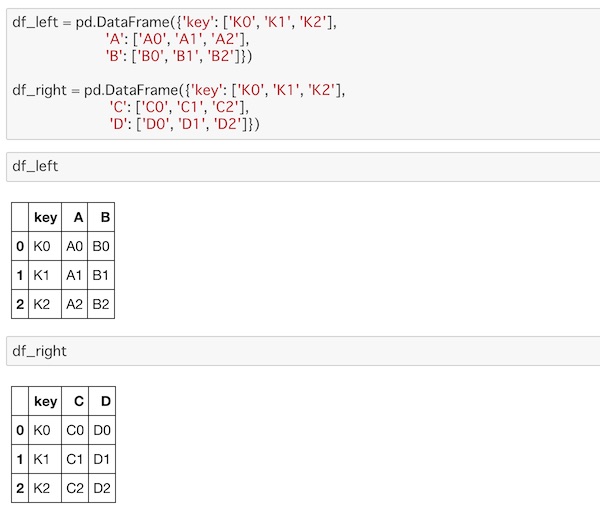
この2つのDataFrameをmerge()に渡して連結してみます。
pd.merge(df_left,df_right)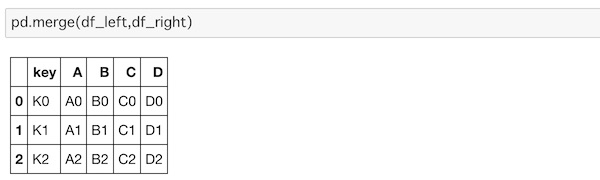
次元も揃っているのでキーを共通にして連結されています。これは見やすくてわかりやすいと思います。
では、今度は次のように複雑なDataFrameを作ってみます。
df_left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df_right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})2つのキーが共通していますが、その値はそれぞれ違います。
それぞれ表示すると次のようになります。
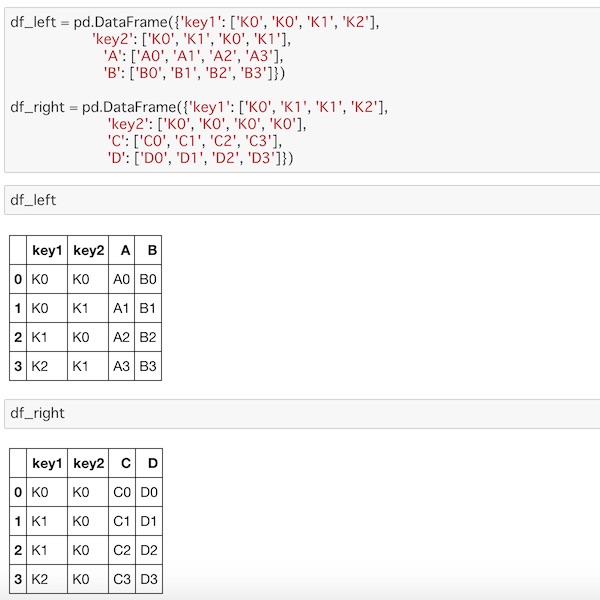
この2つのDataFrameをこれまでと同様にmerge()してみます。
pd.merge(df_left, df_right)
2つのDataFrameに共通しているkey1, key2を軸に連結されますが、さらにそのkey1, key2の値でどちらにも共通している値を持つ部分でされています。
この複雑なDataFrameをさらに違う操作で値を取得することができます。それには、howキーワードとonキーワードを使います。
onキーワードで明示的に列名を与えて、howキーワードにouterを指定して外部結合させてみます。
pd.merge(df_left, df_right, how='outer', on=['key1', 'key2'])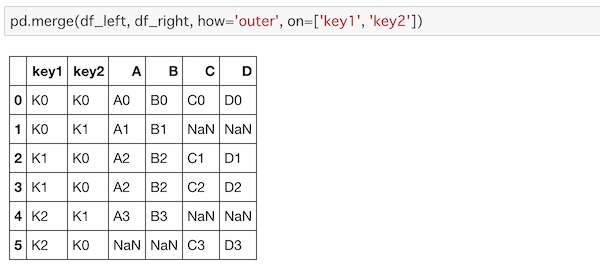
全ての要素が結合されて、値の無い部分にNaNが入れられているのがわかります。集合和の形ですね。
このhowにはleft, rightを指定して、それぞれ左、右のデータセットに存在する行に合わせてデータを結合できます。
まずhow=’right’で右結合してみましょう。
pd.merge(df_left, df_right, how='right', on=['key1', 'key2'])
df_rightのkey1, key2に合わせて結合されているのがわかります。要素の無い部分にはNaNが入っています。
今度はhow=’left’で左結合してみます。
pd.merge(df_left, df_right, how='left', on=['key1', 'key2'])
df_leftのkey1, key2に合わせて結合され、要素の無い部分にNaNが入っています。
join()
最後にJoin()を見ていきます。
join()は異なるインデックスを持つ2つのDataFrameを1つに結合する方法です。
次のindexの異なる2つのDataFrameを用意します。
df_left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
df_right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])DataFrameをjoin()で結合するには次のように行ないます。
df_left.join(df_right)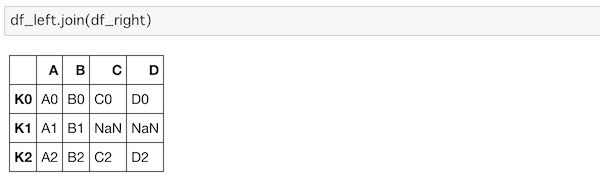
df_leftのインデックスに合わせて結合されているのがわかります。
今度はこれに、how=’outer’を指定して外部結合させてみます。
df_left.join(df_right, how='outer')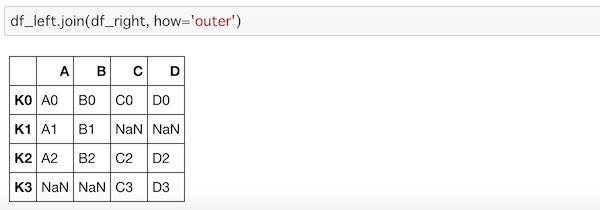
要素の無い部分にNaNを入れて、2つのDataFrameが全て結合されているのがわかります。
最後に
ここでは、Pythonの拡張モジュールPandasのDataFrameの結合を見てきました。
PandasにはDataFramesを組み合わせる方法として主に3つの方法があります。
concate()、merge()、Join()の3つです。
これらを使ってDataFremeの結合を見てきましたが、それぞれの機能の特徴をよく理解しましょう。

